论文阅读_PaLM
name_ch: PaLM:使用 Pathways 的扩展语言建模
name_en: PaLM:Scaling Language Modeling with Pathways
paper_addr: http://arxiv.org/abs/2204.02311
date_publish: 2022-10-05
读后感
论文主要介绍了 Google 的超大模型 PaLM,它在多数任务上都超过了 SOTA,其主因是使用模型使用了大量参数和数据训练,作者认为当模型大到一定程度后,其性能也能飞跃,而 PathWay 技术是其大规模训练的基础。
和其它模型相比,PaLM 更关注逻辑推理相关的任务,这也为后面的 PaLM-E 机器人行为规划奠定了基础。
动态路由层选择具体的路怎么走。
摘要
文中提出了 Pathways Language Model (PaLM),使用 6144 个 TPU v4 芯片训练,模型 540 B 参数,780 B 高质量 token,密集激活,Transformer 语言模型。在推理任务上表现很好,文中提出:扩展到巨大模型后,性能急剧提高(Pathways 是 Jeff Dean 与 2021 年提出的一种谷歌通用 AI 架构,可高效利用硬件)。
1. 介绍
一般大模型的优势主要来自以下:
缩放模型的深度和宽度;
增加训练模型的 token 数量;
对来自更多不同来源的更干净的数据集进行训练;
通过稀疏激活模块在不增加计算成本的情况下增加模型容量。
本文的主要工作包括:
- 使用 Pathway 有效地训练大模型,高效利用硬件
- 随着更大的模型规范,模型效果不断改善
- 在理解、推理等困难任务上展示了突破性能力
- 模型从 62B 变成 540B 后,模型效果出现跨越式(非连续)地进步
- 测试了英文及其它语言(其它语言语料的<22%)
- 在偏见和毒性测试中发现大模型相对毒性更高,且毒性与提示文本设计有关
2. 模型结构
PaLM 与 GPT-3 模型一样,只使用 Decoder 结构。优化技术如下:
SwiGLU 激活函数
组合了 Swish 和 GeLU 两种激活函数。
平行层
将串行变为平行操作(由于 MLP 和注意力输入矩阵乘法可以融合),提速 15%,且实验证明不影响模型效果。
$$
y = x + MLP(LayerNorm(x + Attention(LayerNorm(x))) $$
变为:
\[ y = x + MLP(LayerNorm(x)) + Attention(LayerNorm(x)) \]
多 Query 注意力
标准的多头注意力在自回归解码期间在加速器硬件上的效率很低,因为键/值张量在示例之间不共享。文中模型让 key/value 映射被每个头共享,而 Query 相互独立,该方法提升了解码器的自回归时间。
RoPE 嵌入
RoPE:rotary position embedding 旋转位置嵌入,是一种相对位置嵌入,它不同于绝对位置嵌入和一般的相对位置嵌入,它对长序列效果更好。
共享输入输出嵌入
输入和输出共享同一个嵌入矩阵,从而减少了模型的参数数量,提高了模型的效率。
无 Biases
网络层不使用 biases,可以增加大模型的训练稳定性。
词表
使用 SentencePiece(通过统计方法,将频繁出现的字符串作为词,然后形成词库进行切分),使切分的粒度会更大一些。使用 256K 的 token 表,词表以外的文本被切分成 utf-8 字符。
模型规模超参数
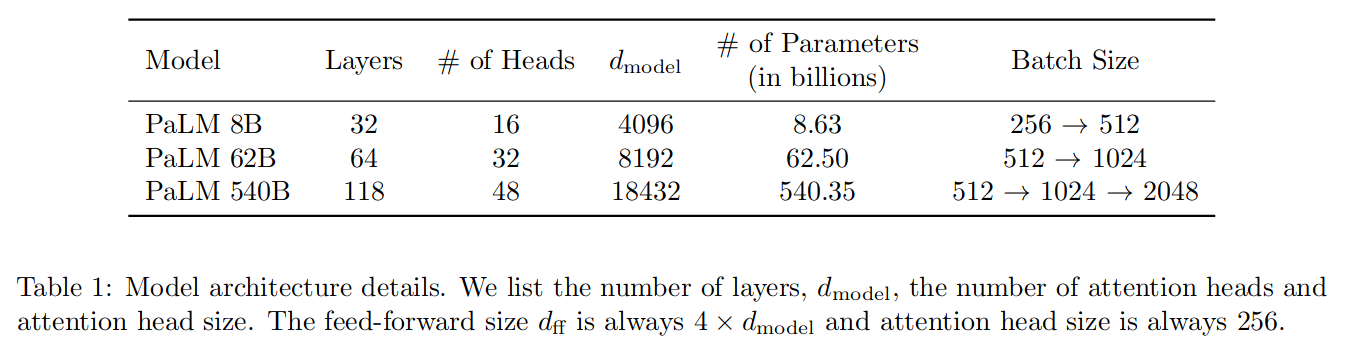
3. 训练数据
780 B 高质量的 token。数据基于训练 LaMDA 和 GLaM 的数据,除了自然语言,还包含多种编程语言的源代码。根据文件之间的 Levenshtein 距离删除重复项。

4. 训练基础设施
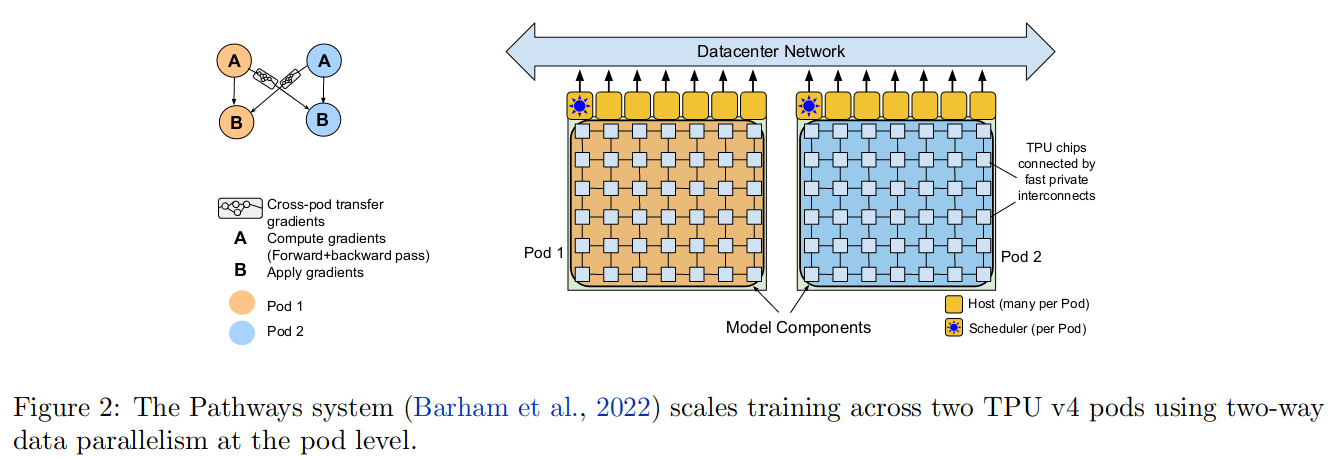
使用 PathWay 方法训练模型,在两个 TPU v4 Pods 上训练,在每个 Pod 中包含由 3072 个 TPU v4 芯片链接的 768 个主机。允许在不使用任何 pipeline 并行的情况下高效的在 6144 个芯片上训练。
pipeline 方式有更多的相互等待时间,而 pathway 复杂度更高。每个 TPU v4 Pod 都包含模型参数的完全拷贝。
详见:Pathway 原理。
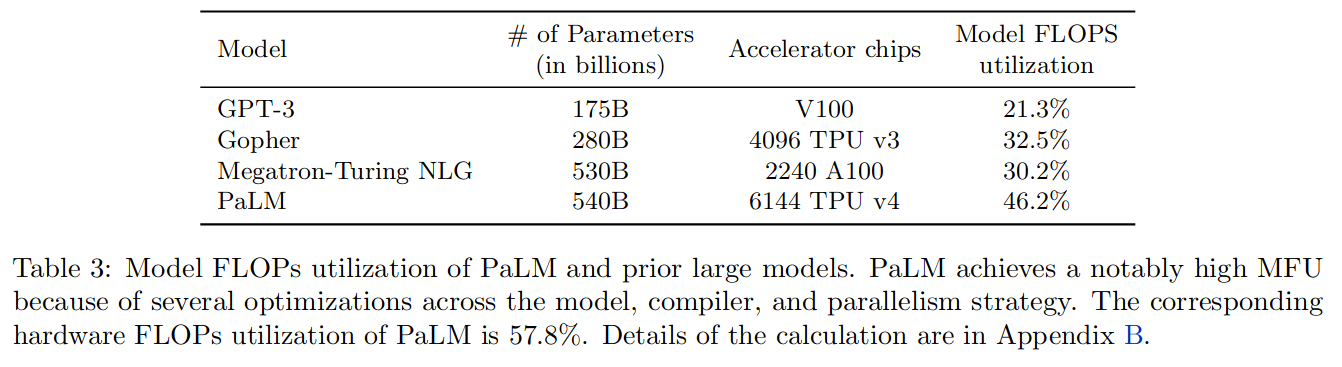
相比之前模型,PaLM 在由于对模型、编译器和并行策略进行了多项优化,实现了非常高的 MFU,对应的硬件 FLOPs 利用率也更高。
5. 训练设置
此节介绍了权重初始值,优化器,超参数,损失函数,序列长度,Batch 大小,Dropout 比例等细节。
6. 评测
论文在:英文 NLP 任务,BIG_bench,推理,代码任务,翻译,多语言生成方面对 PaLM 进行了评测。
6.1 英文 NLP 任务
PaLM 在 1-shot 设置下,在 29 个任务中的 24 取得了 SOTA;在 few-shot 设置下,在 29 个任务中的 28 个取得了 SOTA。分为自然语言理解和自然语言推理,平均分如下:
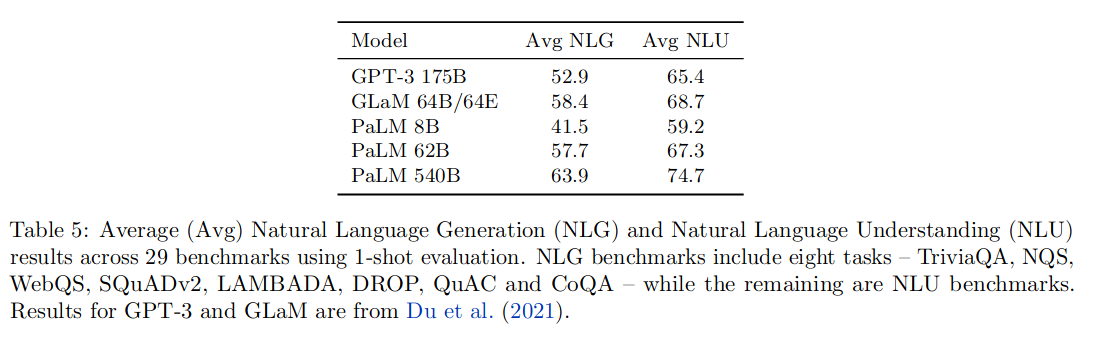
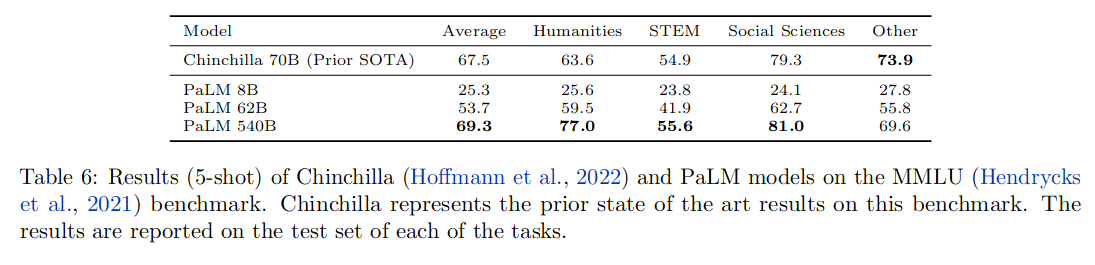
MMLU 评测结果如下:
6.2 BIG-bench 任务
BIG-bench 包括 150 多个任务,涵盖各种语言建模任务,包括逻辑推理、翻译、问答、数学等。除了模型之间的对比,还对比了人类的平均水平和最佳水平。
PaLM 540B 5-shot 在 58 项常见任务中的 44 项上优于之前的 SOTA,
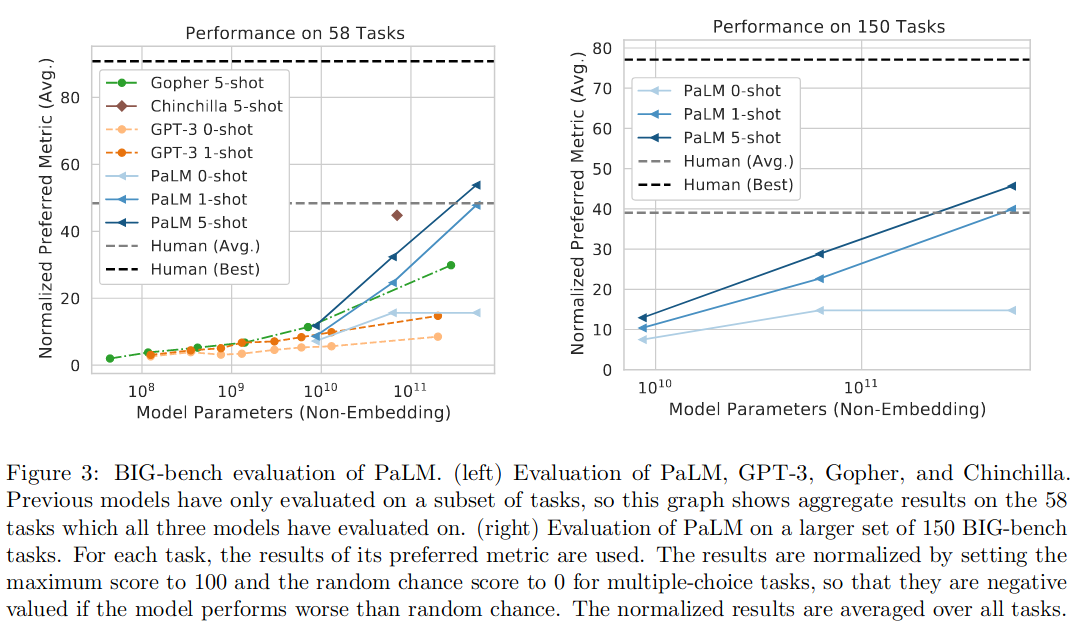
需要注意的是其中有一些推理相关的项目,效果如图 -5 所示:
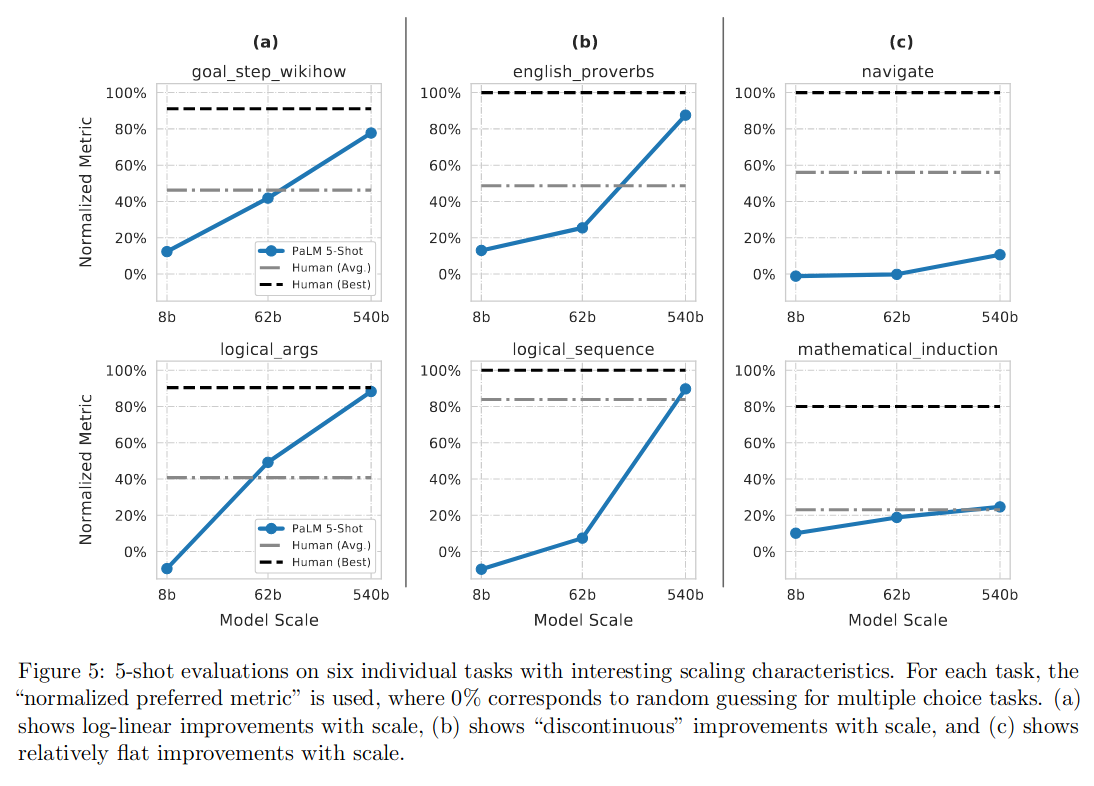
可以看到,有几项接近了人类的最佳水平,也可以看到,当模型从 62B 变为 540B 时,模型效果有了跨越式的提升。
另外,PaLM540B 在多数评测中高于人类的平均水平,有 35% 低于人类平均。
6.3 推理
推理任务分为两类:
- 算术推理:通常涉及小学水平的自然语言数学问题,需要多步逻辑推理。其难点是将自然语言转化为数学方程式。
- 常识推理:需要很强的世界知识的问答任务,而不是简单的事实问答。
这种问题一般需要输出答案和推理过程。具体调优方法是使用思维链提示学习,提示学习时只使用了 8-shot 样本。从表 -10 中可以看到不同方式对结果的影响。

还进行了其它的推理评测,结果是推理链提示和大模型都明显提升了模型的推理能力。
6.4 代码任务
代码任务一般包括:根据文本描述写代码,把一种语言的代码翻译成另一种,以及代码修复。训练和精调时都包含一些代码数据,使得模型具有编码能力。PaLM 540B 有一定的代码能力,PaLM-Coder 则是在代码上微调的模型。微调能够显著的改善 PaLM 在代码任务上的效果。
6.5 翻译
评测主要关注三类问题:
- 以英语为中心的语言对:PaLM 优于所有基线,有些甚至优于监督基线。
- 直接语言对(在不涉及英语的情况下直接翻译),PaLM 仅在法语 - 德语上匹配监督表现。
- 资源极少的语言对(如哈萨克 - 英语翻译),能够在德语 - 法语和哈萨克语 - 英语上给出很强的表现。
6.6 多语言生成
实验分别测试了 1-shot 和 Finetuning 的结果,第一组评测是将数据转换成文本,第二组评测以总结文本为主,可以看到,PaLM 在 1-shot 中表现优于其它模型,PaLM 模型越大,提升效果越明显;finetuning 使各模型效果都有提升。
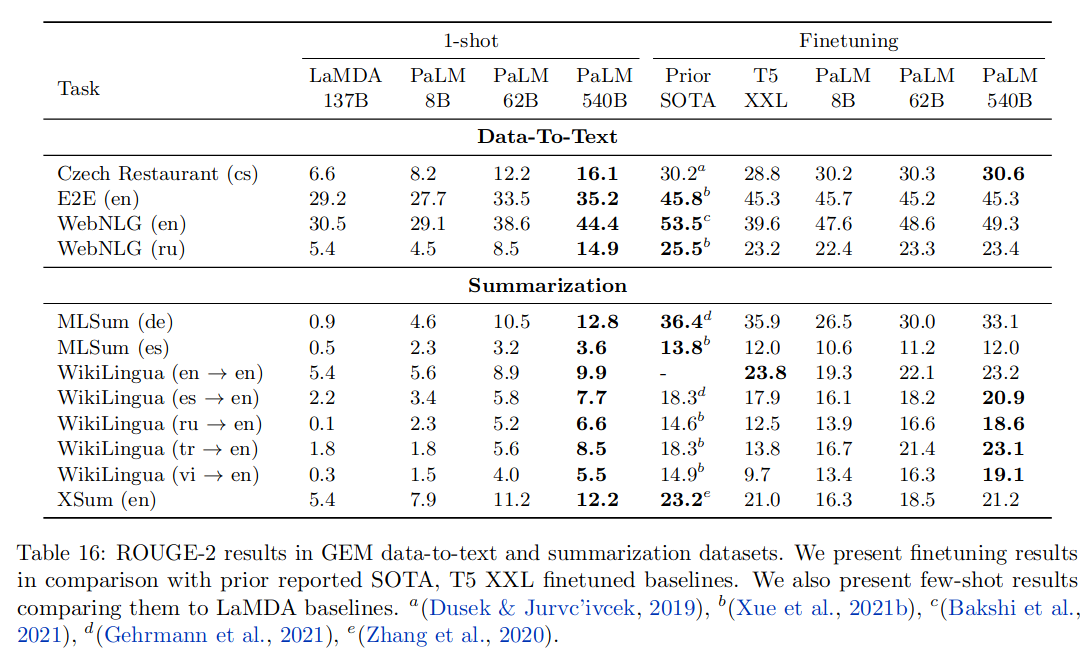
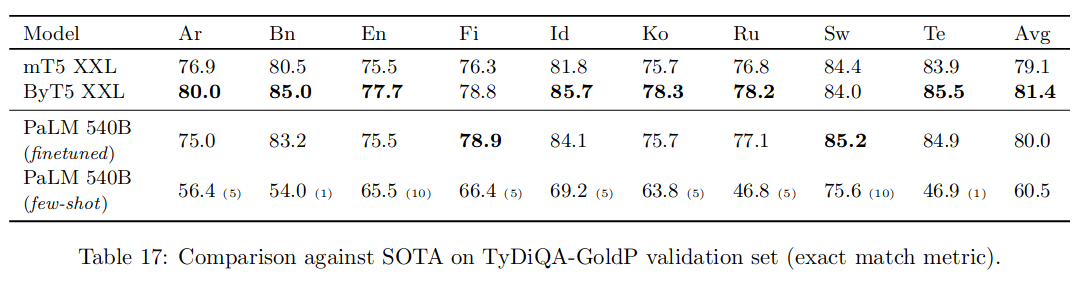
6.7 多语言问答
可以看到 PaLM 精调后效果有明显提升,效果不如 T5,可能是由于 mT5 和 ByT5 接受的非英语文本训练分别是 PaLM 的 6 倍和 1.5 倍。
6.8 分析
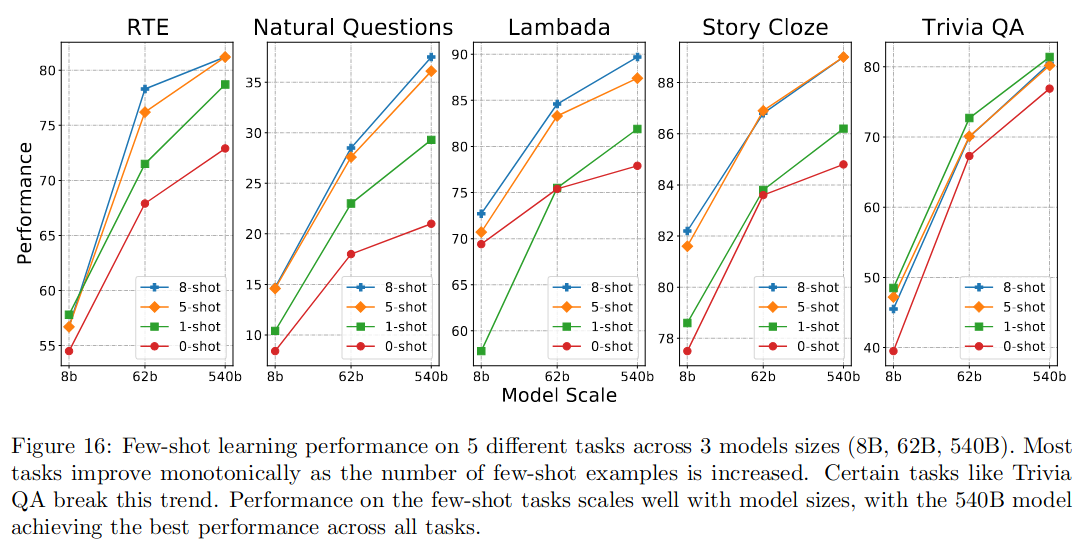
随着给模型提供更多示例,性能会提高。
7,8 略
9. 探索解释
使用思维链提示调优模型,提高多步推理任务中的预测准确性,可以用于模型解释。
解释包含以下场景:
- 了解模型是否出于“正确的原因”而产生正确的答案,而不是仅仅进行表面层面的统计推断,具有重大的科学意义。
- 解释可能会显示给系统的最终用户,以增加或减少他们对给定预测的信心。
- 在许多情况下(例如,解释一个笑话),解释本身就是期望的输出。
此部分列举了解释的两种场景:解释笑话,逻辑推理。对于每项任务,都编写了 2-shot 示例来演示所需的输出样式,作为例子提示模型。具体见图 -19。
笑话示例:
输入:我打算在 4 月 6 日飞去探望我的家人。我妈妈说:“太好了,那天晚上你继父的诗歌朗诵会!”所以现在我要在 4 月 7 日飞来。
模型输出:这个笑话是说话者的母亲试图让他们去他们继父的诗歌朗诵会,但说话者不想去,所以他们将航班改到诗歌朗读后的第二天。
推理示例:
输入:迈克尔在法国那个非常有名的博物馆里看它最著名的画作。然而,创作这幅画的艺术家恰恰让迈克尔想起了他小时候最喜欢的卡通人物。卡通人物平时手里拿的东西是哪个国家的?
模型输出:卢浮宫最著名的画作是蒙娜丽莎。制作蒙娜丽莎的艺术家是达芬奇。Leonardo da Vinci 也是卡通忍者神龟中主角的名字。列奥纳多·达·芬奇来自意大利。列奥纳多·达·芬奇平时手里拿着的东西是武士刀。武士刀的原产国是日本。答案是“日本”。
参考
https://zhuanlan.zhihu.com/p/602060627