退一步:通过唤起推理
1 | 英文名称: TAKE A STEP BACK: EVOKING REASONING VIA ABSTRACTION IN LARGE LANGUAGE MODELS |
摘要
- 目标:提出一种简单提示技术 Step-Back Prompting,鼓励模型在处理问题之前先进行抽象化,即从具体实例中提取出高层次的概念和原则,然后再用这些概念和原则来指导后续的推理过程。
- 方法:主要分为两个步骤,抽象:提出一个抽象的提问,以激发模型对更高层次概念或原理的思考;推理:使用抽象概念或原理来回答原始问题。
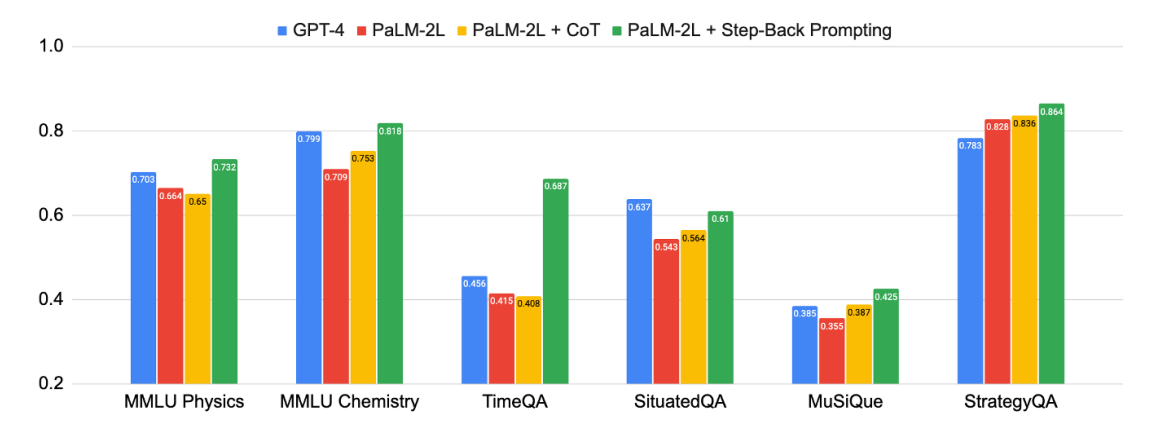
- 结论:实验结果显示,Step-Back Prompting 显著提高了 LLMs 在 STEM、知识问答和多跳推理等任务中的表现。例如,Step-Back Prompting 使 PaLM-2L 在 MMLU(物理和化学)的表现分别提高了 7% 和 11%,TimeQA 提高了 27%,MuSiQue 提高了 7%。
读后感 vs 思考
用户经常提出各式各样的问题,我们通常会把这些问题和之前的对话上下文直接交给 LLM 处理。具体问题往往包含大量的细节,而这些细节在大模型的训练数据中并未出现,因此,只能依赖大模型本身的泛化能力。然而,目前看来,对于需要多步骤的复杂问题,大模型的处理能力还相当有限。
过去有人认为,如果大模型足够智能,上下文支持足够充分,那么我们就不需要进行任何前处理和后处理。但实际情况是,至少在一段时间内,分步处理仍然是必要的。
可以考虑两种场景,一种是用户一次只提一个问题,与上下文无关;另一种是用户进行连续的对话。先看一下第一种相对简单的场景,是否可以像使用万能公式提示一样,从用户的问题中提取各种特征,然后以某种格式组装后再提交给 LLM,或者分流,这样的效果是否比直接提交更好。本文通过实验验证,这样的方法确实能带来更好的效果。
实现
当面对具有挑战性的任务时,人类经常采取一种抽象的策略,以便从更高层次的概念和原则进行引导和指导。这就引出了我们的“退后一步提示”,它的核心是以抽象为基础进行推理,以此来减少在推理过程中出现错误的机会。
"STEP-BACK PROMPTING" 主要包括两个步骤:
第一步,抽象(Abstraction):并不是直接回答问题,而是首先提示提出一个更高层次的概念或原则的通用问题,然后寻找与这些高级概念或原则相关的信息。
第二步,推理(Reasoning):有了这些高级概念或原则的信息后,可以进行推理,找出原始问题的解决方案。称之为基于抽象的推理。
应用
langchain 实现了 stepback-qa 逻辑:
- stepback-qa: https://github.com/langchain-ai/langchain/blob/master/cookbook/stepback-qa.ipynb
- langchain-ai/stepback-answer: https://smith.langchain.com/hub/langchain-ai/stepback-answer?ref=blog.langchain.dev
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.