论文阅读_中文语言技术平台LTP
1 | 英文题目:N-LTP: An Open-source Neural Language Technology Platform for Chinese |
1 读后感
它是一个基于Pytorch的针对中文的离线工具,带训练好的模型,最小模型仅 164M。直接支持分词,命名实体识别等六种任务,六种任务基本都围绕分词、确定词的成份、关系。
实测:比想象中好用,如果用于识别人名,效果还可以,直接用于垂直领域,效果一般,可能还需要进一步精调。
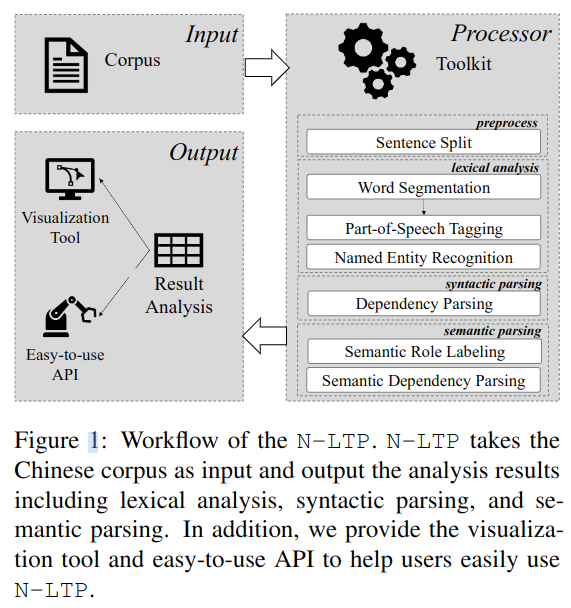
2 介绍
2.1 文章贡献
- 支持六项中文自然语言任务。
- 基于多任务框架,共享知识,减少内存用量,加快速度。
- 高扩展性:支持用户引入的 BERT 类模型。
- 容易使用:支持多语言接口 C++, Python, Java, Rust
- 达到比之前模型更好的效果
3 设计和架构
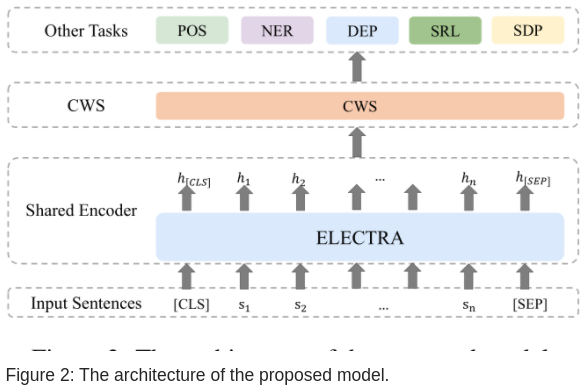
图 -2 展示了软件架构,由一个多任务共享的编码层和各任务别实现的解码层组成。
3.1.1 共享编码层
使用预训练的模型 ELECTRA,输入序列是 s=(s1,s2,...,sn),加入符号将其变成 s = ([CLS], s1, s2,..., sn, [SEP]),请见 BERT 原理,输出为对应的隐藏层编码
H = (h[CLS],h1, h2,..., hn, h[SEP])。
3.1.2 中文分词 CWS
将编码后的 H 代入线性解码器,对每个字符分类:
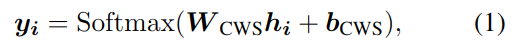
y 是每个字符类别为各标签的概率。
3.1.3 位置标注 POS
位置标注也是 NLP 中的一个重要任务,用于进一步的语法解析。目前的主流方法是将其视为序列标注问题。也是将编码后的 H 作为输入,输出位置的标签:
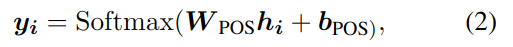
y 是该位置字符属于某一标签的概率,其中 i 是位置信息。
3.1.4 命名实体识别 NER
命名实体识别的目标是寻找实体的开始位置和结束位置,以及该实体的类别。工具中使用 Adapted-Transformer 方法,加入方向和距离特征:
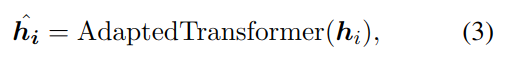
最后一步也使用线性分类器计算每个词的类别:
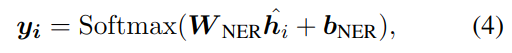
其中 y 是 NER 属于某一标签的概率。
3.1.5 依赖性解析 DEP
依赖性解析主要是分析句子的语义结构(详见网上示例),寻找词与词之间的关系。软件中具体使用了双仿射神经网络和 einser 算法。
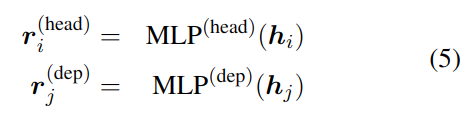
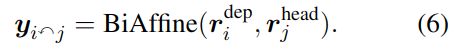
3.1.6 语义依解析 SDP
与依赖性分析相似,语义依赖分析也是捕捉句子的语义结构。它将句子分析成一棵依存句法树,描述出各个词语之间的依存关系。也即指出了词语之间在句法上的搭配关系,这种搭配关系是和语义相关联的。具体包括:主谓关系 SBV,动宾关系 VOB,定中关系 ATT 等,详见:
具方法是查找语义上相互关联的词对,并找到预定义的语义关系。实现也使用了双仿射模型。
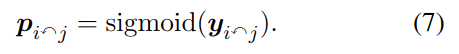
当 p>0.5 时,则认为词 i 与 j 之间存在关联。
3.1.7 语义角色标注 SRL
语义角色标注主要目标是识别句子以谓语为中心的结构,具体方法是使用端到端的 SRL 模型,它结合了双仿射神经网络和条件随机场作为编码器,条件随机场公式如下:
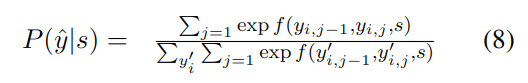
其中 f 用于计算从 yi,j-1 到 yi,j 的转移概率。
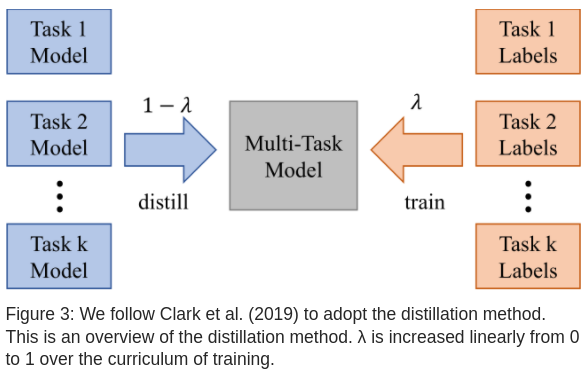
3.1.8 知识蒸馏
为了比较单独训练任务和多任务训练,引入了 BAM 方法:
4 用法
4.1 安装
1 | $ pip install ltp |
4.2 在线 demo
http://ltp.ai/demo.html
4.3 示例代码
4.3.1 旧 API
1 | from ltp import LTP |
其中 seg 函数实现了分词,并输出了切分结果,及各词的向量表示。
4.3.2 新 API
(220923)
1 | output = ltp.pipeline(["他叫汤姆去拿外衣。"], tasks=["cws", "pos", "ner", "srl", "dep", "sdp"]) |
4.4 精调模型
下载源码
1 | $ git clone https://github.com/HIT-SCIR/ltp |
在其 ltp 目录中有 task_xx.py,可训练及调优模型,用法详见 py 内部的示例。形如:
1 | python ltp/task_segmention.py --data_dir=data/seg --num_labels=2 --max_epochs=10 --batch_size=16 --gpus=1 --precision=16 --auto_lr_find=lr |
5 实验
Stanza 是支持一个多语言的 NLP 工具,中文建模效果比较如下:
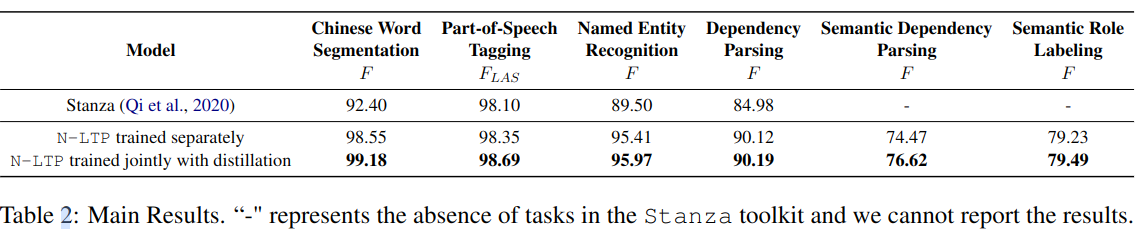
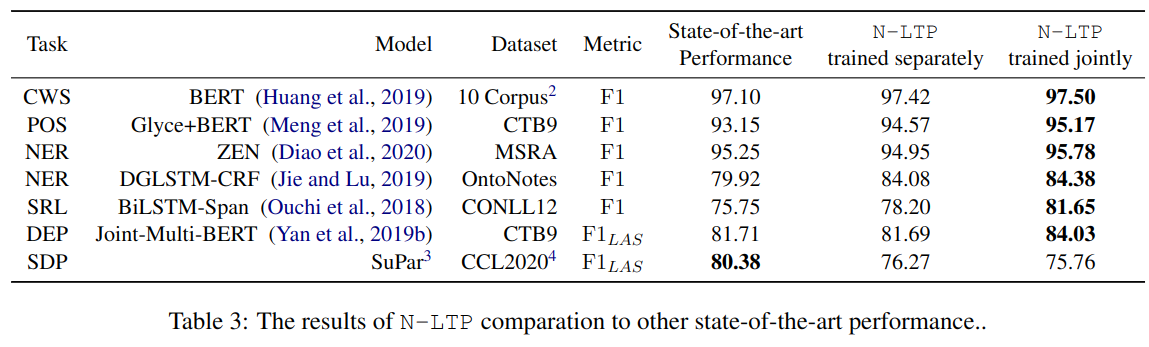
另外,实验也证明,使用联合模型速度更快,占用内存更少。
6 使用方法
- 需要从 huggingface 下载模型,详见 README.md
- 模型都不大,每个几百兆
- CPU 版本转换一句不到 1s,大概 50 句/秒
- 当前版本(230911)感知机算法 Legacy 模型速度非常快,是 LTP v3 的 3.55 倍,开启多线程更可获得 17.17 倍的速度提升,但目前仅支持分词、词性、命名实体任务