论文阅读_ICD编码_TLSTM
介绍
英文题目:A Neural Architecture for Automated ICD Coding
中文题目:ICD 自动编码的神经体系结构
论文地址:http://www.cs.cmu.edu/~epxing/papers/2018/Xie_etal_acl18.pdf
领域:自然语言处理,生物医疗
发表时间:2018
作者:Pengtao Xie 等,卡内基梅隆大学,北京大学
出处:ACL 2018
被引量:55
阅读时间:2022.06.18
读后感
论文主要挖掘了ICD 编码之间的层级和相关性,同时还考虑到人工描述和 ICD 标准文本不同的语言风格,一对多的情况下,多个对应项的重要性排序,以及编码的协同和互斥。
泛读
- 针对问题:ICD 自动编码
- 核心方法:
- 使用树和序列 LSTM 计算基于语义的 ICD 编码表示
- 使用对抗学习协调人工输入和 ICD 描述的语言风格
- 利用等张约束做重要性排序
- 利用注意力机制实现一对多、多对一映射
- 泛读后理解程度:
- 一个半小时精读,两个小时整理。
方法
概览
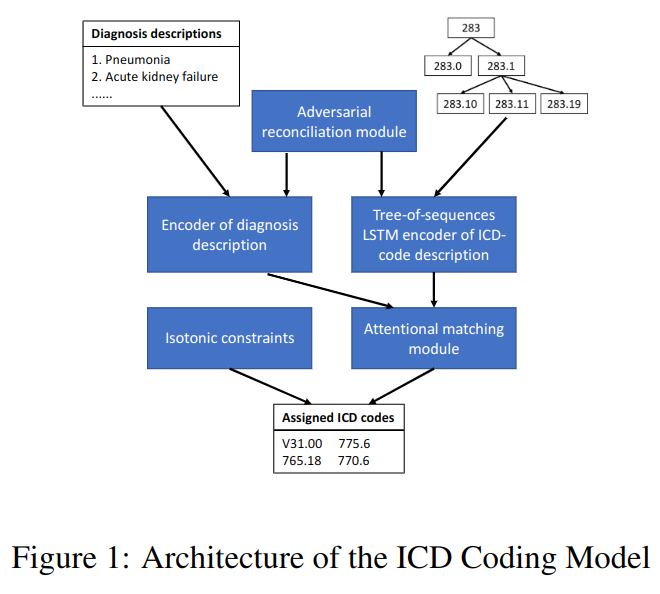
图 -1 左上描述的是人工书写的诊断信息,右上是 ICD 编码树,蓝色方块是处理流程,下方的 ICD 编码是模型输出。
树序列的 LSTM 编码
ICD 编码模型希望在捕捉语义的同时也捕捉到编码的层次关系。
每个 ICD 编码对应一小段描述文字,使用普通 SLSTM(序列 LSTM)对每一条 ICD 项编码,使用 TLSTM(树 LSTM)构建整体的编码树 (code tree),以捕捉 ICD 编码的层次关系,每个树节点的输入向量是 SLSTM 产生的向量表示。
序列 LSTM
序列 LSTM 就是最普通的 LSTM,包含输入门 i,输出门 o,遗忘门 f,和记忆单元 c:
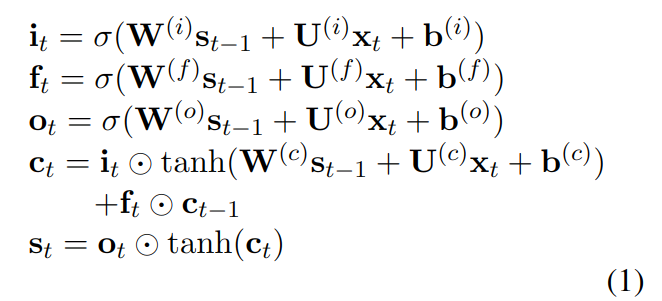
树序列 LSTM
这里使用了双向树 TLSTM,输入是 ICD 编码的层级关系和通过 SLSTM 提取的各节点的表示。具体包含自下而上和从上而下两部分,对树中各节点产生了对应的两个 h 表示。
自下而上时,编码 C,有 M 个子编码,它的遗忘层计算了其 m 个子节点:
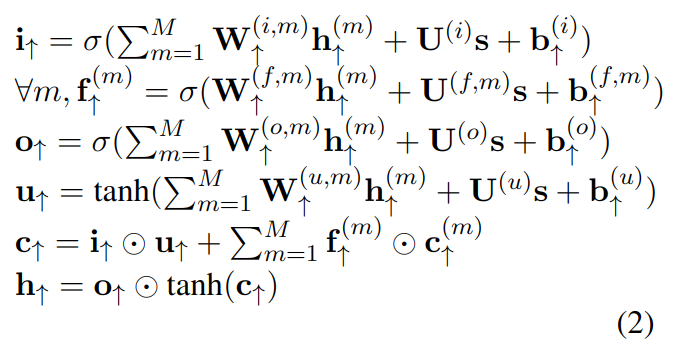
其中 s 是用 SLSTM 输出的各个节点的表示,h 和 c 由其子节点的隐藏层和记忆单元组合得到。W,U,b 是模型参数。叶节点无子节点,因此它只考虑 s。
从上而下时,对于非根节点,计算方法如下:
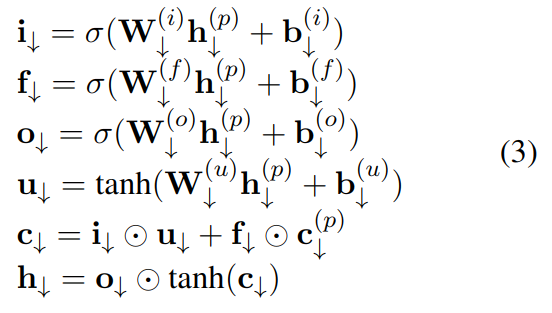
其中带 (p) 上标的是父节点。由于根节点没有父节点,其 h(p) 就使用从上而上时计算出来的表示,它捕捉了其下所有子节点的语义信息,通过自上而下的计算,又迭代计入了其下的子节点。
最后,串联自上而下和自下而上的 h 作为节点的表示:h=[h↑; h↓],从而获取了结构关系。
对于人工输入的诊断描述,也使用 SLSTM 编码。参数权重与计算 ICD 编码时 SLSTM 的参数权重绑定在一起。
注意力匹配
使用 h 代表人工描述的表示,u 代表 ICD 代码的表示,M 是某患者的描述个数,N 表示 ICD 编码总量。当一个描述实例对应多个 ICD 编码时,K 代表对应的 ICD 代码个数。各编码的重要程度不同,可以认为其余 M-K 个编码的重要程度为 0。使用注意力机制计算重要性得分(u 和 h 越相近,注意力权重越大):
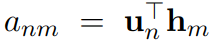
然后,进一步对注意力值做归一化,计算出该输入对应编码 n 的表示:
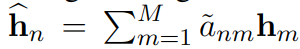
而后串联 hn 和 un,并将其代入线性分类器,用于预测命中该编码的概率:
\[ p_n=sigmoid(w_n^\intercal[\hat h_n;u_n]+b_n) \]
其损失函数计算如下:
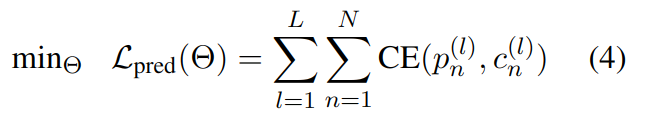
其中 CE 是交叉熵,Θ表示所有可调参数,L 是实例条数,N 是 ICD 编码总数,c 是实际是否命中该 ICD 编码,命中为 1,否则为 0。
针对写作风格的对抗学习
利用对抗学习来调和人工描述 (DD) 和 ICD 规范文本 (CD) 间的风格差异。对抗网络由两部分组成,一部分是判别网络,将嵌入向量作为输入,目标是区分 DD 和 CD。另一部分编码网络(共享 SLSTM),通过对 DD 和 CD 的编码器训练,尽量使判别器无法区分二者。这样调整后的编码器,就能更好地匹配 CD 与 DD。
损失函数如下:
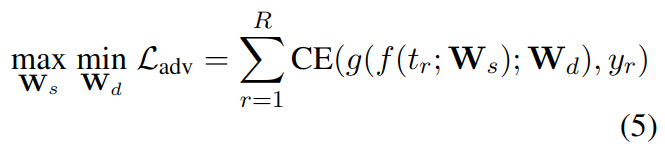
其中 y 是标签,tr 是文本描述,f 函数是 SLSTM 模型,Ws 是 SLSTM 模型参数,g 是判别网络,Wd 是判别模型参数。
等渗约束
使用上面提到的预测概率来表示 ICD 编码的重要性,因此,通过优化损失函数,加入对 p 的约束。可实现对 ICD 编码的排序。
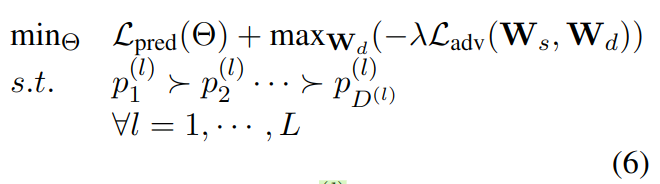
其中λ是权衡参数。