论文阅读_清华ERNIE
英文题目:ERNIE: Enhanced Language Representation with Informative Entities
中文题目:ERNIE: 使用信息实体增强语言表示
论文地址:https://arxiv.org/pdf/1905.07129v3/n
领域:自然语言处理
发表时间:2019
作者:Zhengyan Zhang,清华大学
出处:ACL
被引量:37
代码和数据:https://github.com/thunlp/ERNIE
阅读时间:2002.06.25
读后感
2019 年前后清华和百度都提出了名为 ERNIE 的模型,名字相同,方法不同。清华的 ERNIE 把知识图融入了文本的向量表示,也叫 KEPLM,想法比较有意思,模型改进效果:使用少量数据训练模型时,ERNIE 比其它模型效果更好。从技术角度,它示范了整合异构数据的方法。
介绍
本文提出 ERNIE,它是结合知识图和大规模数据的预训练语言模型。引入知识图面临两个重要挑战:
- 如何在文本表示中提取和表示知识图中的结构
- 整合异构数据:将预训练模型表示和知识图表示映射到同一向量空间
ERNIE 的解决方法如下:
- 识别文本中提到的命名实体,然后将实体与知识图中对应的实体对齐,利用文本语义作为知识图的实体嵌入,再使用 TransE 方法学习图的结构。
- 在预训练语言模型方面,也使用类似 BERT 的 MLM 方法,同时利用对齐方法,找知识图中的实体做遮蔽;聚合了上下文和知识图共同预测 token 和实体。
方法
定义符号
token(操作的最小单位:一般是字或词)使用 {w1,...,wn} 表示,对齐后的实体用 {e1,..., em} 表示。需要注意 m 与 n 一般个数不同,实体可能包含不只一个字或词。定义 V 为包含所有 token 的词表,知识图中的所有实体用 E 表示。用函数 f(w)=e 表示对齐函数,文中使用实体中的第一个 token 对齐。
模型结构
模型结构如图 -2 所示:
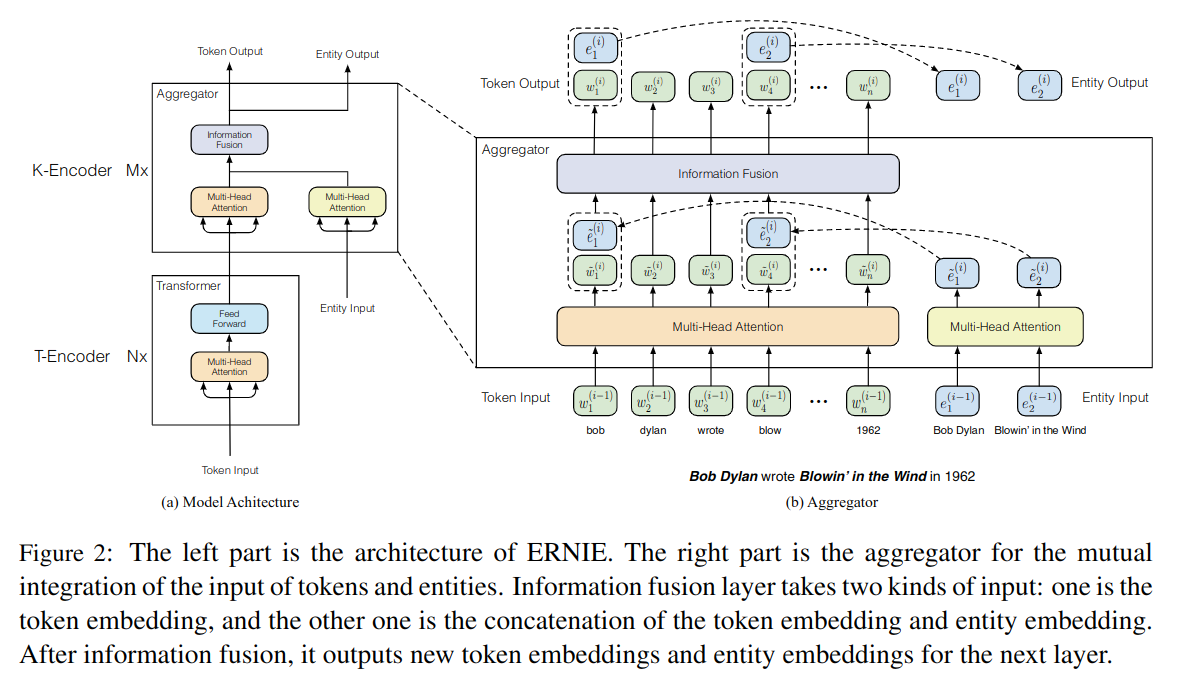
模型结构包含两块,T-Encoder 用于提取 token 相关的文本信息;K-Encoder 整合了扩展的图信息,将异构数据转换到统一的空间中。
首先,将利用 token {w1,..., wn} 的词嵌入、段嵌入、位置嵌入,代入 T-Encoder 层,计算其语义特征:

T-Encoder 类似普通的 BERT,它由 N 个 Transformer 层组成,用粗体的 {e1,...., em} 表示通过 TransE 预训练的图嵌入,将粗体的 w 和 e 代入 K-Encoder,整合异构数据,生成输出 wo 和 eo:
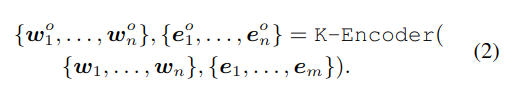
wo 和 eo 将被用于下游任务。
知识编码
从图 -2 的右半部分可以看到,K-Encoder 一般包含 M 层,以第 i 层为例,输入是第 i-1 层的 w 和 e,分别使用两个多头的 self-attention。
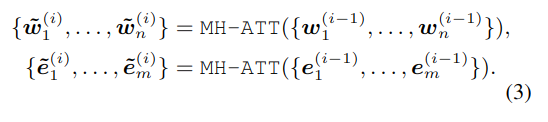
对于 token:wj 和与它对齐的实体:ek=f(wj),使用以下方法融合数据:
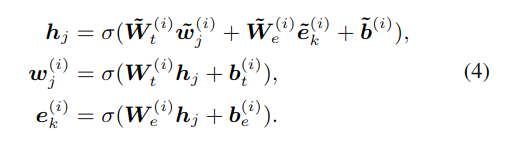
这里的 hj 是内部隐藏层,它结合了 token 和实体表示,σ是非线性激活函数,这里使用 GELU。对于找不到对应实体的 token,无需融合:
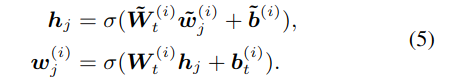
第 i 层简化表示如下:
利用预训练模型注入知识
预训练时,随机遮蔽对齐的 token-entity,让模型预测对应的多个 token。这个过程类似自编码器 dEA。知识图中可能包含非常多的实体,做 softmax 时计算量非常大,而我们只关注系统需要的实体,以减少计算量。在给定 token 序列和实体序列的条件下,定义对齐分布计算:

它计算在 w 条件下,对齐实体为 ej 的概率,式 (7) 用于计算交叉熵损失函数。
在 5% 的情况下,将实体替换成其它实体,以训练模型纠正 token 与实体对齐的错误;在 15% 的情况下,遮蔽 token 与实体间的对齐,以训练模型纠正没有识别到对齐的情况;其它情况保持对齐关系,学习 token 与实体间的关系。
训练的损失函数综合了 dEA(自编码),MLM(遮蔽)和 NSP(句子顺序)的损失。
针对具体任务精调模型
如图 -3 所示:
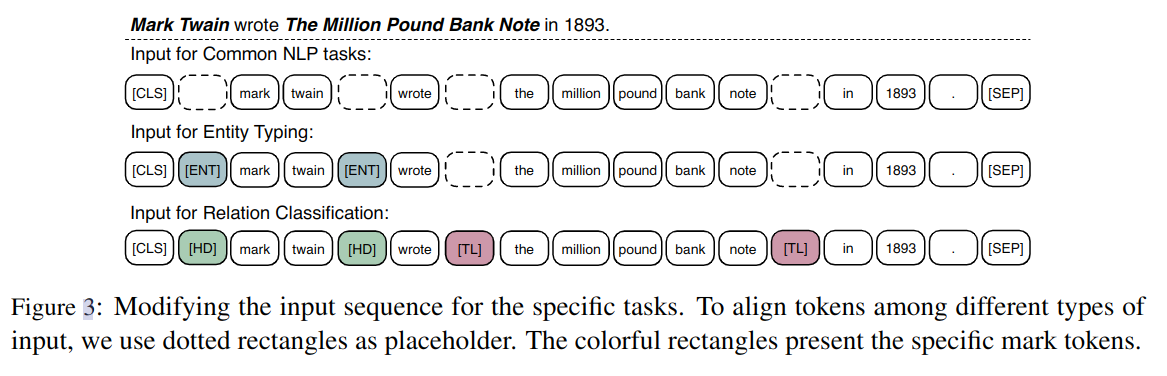
对于一般任务,将编码后的词嵌入代入下游模型即可。对于知识驱动的任务,比如关系分类,或者预测实体类型,使用以下方法精调。
对于关系分类问题,最直接的方法是在输出的实体向量之后加池化层,串联实体对,然后送入分类器。而文中提出的方法如图 -3 所示,它在头实体和尾实体的前后分别加了标签,标签的效果类似于传统关系分类中的位置嵌入,仍然使用 CLS 来标记类别。
预测实体类型是关系分类的简化版,也使用 ENT 标签来引导模型结合上下文信息和实体信息。
实验
清华的 ERNIE 是针对英文训练的模型,实验证明,额外的知识可以帮助模型充分利用小的训练数据,这对很多数据有限的任务非常有用。