论文阅读_图像生成文本_CLIP
读后感
使用大量数据的对比学习,基于对齐图片和文本嵌入的原理,实现了根据图像生成描述文本的功能,为后续根据文本生成图像奠定了基础。
介绍
文中提出 CLIP(Contrastive Language-Image Pre-training)方法,即:对比式语言 - 图像预训练。它的先进性在于:之前模型只能判断图片是否属于固定类别,而它可以根据一张图片内容,生成文本描述,或者利用文本描述的新类别匹配图片,而无需根据新类别调优模型,即零样本学习。
具体实现方法利用少量有标注数据和大量无标注数据(4 亿个图片文本对)方法建模,利用对比学习训练模型,对齐文本和图像的嵌入。通过在 30 多个不同的现有视觉数据集上进行基准测试,证明该模型能很好地应用到大多数任务中。
它为后面一系列的图像生成模型(利用文本生成图片)奠定了基础。比如:用 DALL-E(unCLIP) 用“小狗吹喇叭”自动生成对应的图片。
方法
数据
虽然 MS - COCO 和 Visual Genome 是高质量的人工标记数据集,但按现代标准它们都很小。YFCC100M,在 1 亿张照片中,保留带有自然语言标题和/或英文描述的图片,仅有 1500 万张。这与 ImageNet 的大小大致相同。
CLIP 构建了一个新的数据集,从互联网上的各种公开来源收集了 4 亿 (图像、文字) 对,得到的数据集与用于训练 GPT - 2 的超文本数据集具有相似的总词数,并将该数据集称为 WIT for WebImageText。
方法
将目标定义为:预测文本与图像配对,而不是文本的确切单词。这种方法与之前方法相比大大提升了效率。
下图总结了具体的实现方法,左侧为训练,右测为预测。针对文本 T 和图像 I 分别训练编码器,然后用模型学习正确的配对(对角线上为正确配对);在预测阶段,根据类别生成描述文本,并选择与图片最为匹配的文本作为描述,以实现零样本分类器。
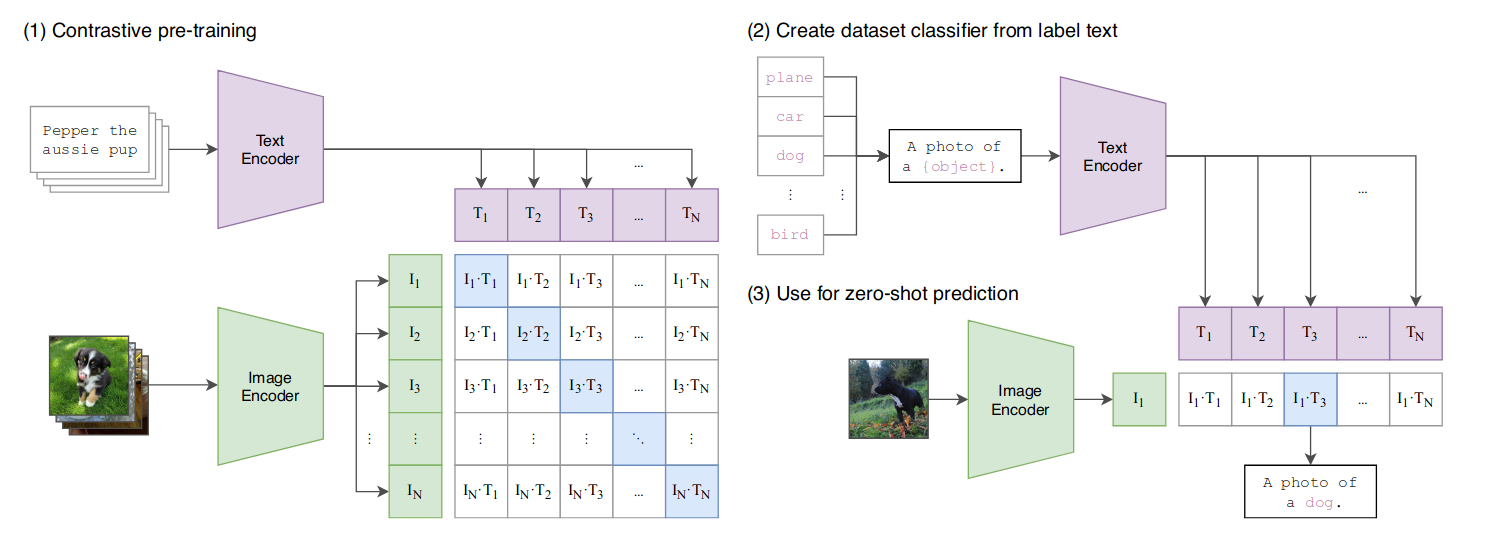
具体训练时,假设一个 Batch 中包含 N 个图文对,则有 NxN 种可能的组合。利用多模态技术,训练图片编码器(如 ResNet)和文本编码器(如 CBOW),将图文转换到嵌入空间,使同一含义的图文表示的 cosine 距离更近,不同含义的距离更远。具体方法如图 -3 所示:

CLIP 使用了大量数据从头训练图片和文本模型参数。并只使用线性投影,将每个编码器的表示映射到多模态嵌入空间。数据增强方法仅使用了从调整大小的图像中随机产生的正方形裁剪。
底层模型
在图像编码器方面尝试了两种架构,一种是在 ResNet 基础版本上做了一些修改,如:锯齿模糊池化,将全局平均池化层替换为注意力池化机制等。另一个是在较新的 Vision Transformer 架构上做了微调。文本编码器使用了 Transformer 模型。在图像的宽度深度扩展方面,使用了 Tan & Le (2019) 提出的 EfficientNet 架构。
实验
实现主要涉及零样本分类问题和表示学习。
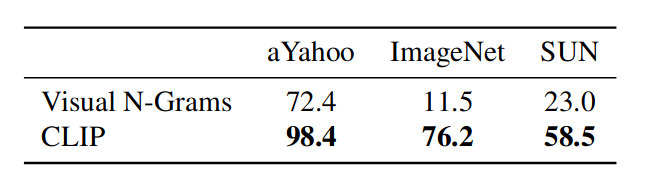
对于零样本迁移图像分类结果,和 Visual N-Grams 对比结果如下(当然 CLIP 计算量也大得多):
另一方面也讨论了模型表征学习的能力,评测时使用的主要方法是:在从模型中提取的表示上拟合一个线性分类器,并在各种数据集上测量其性能。以评测与任务无关的数据表征,对比效果如下:
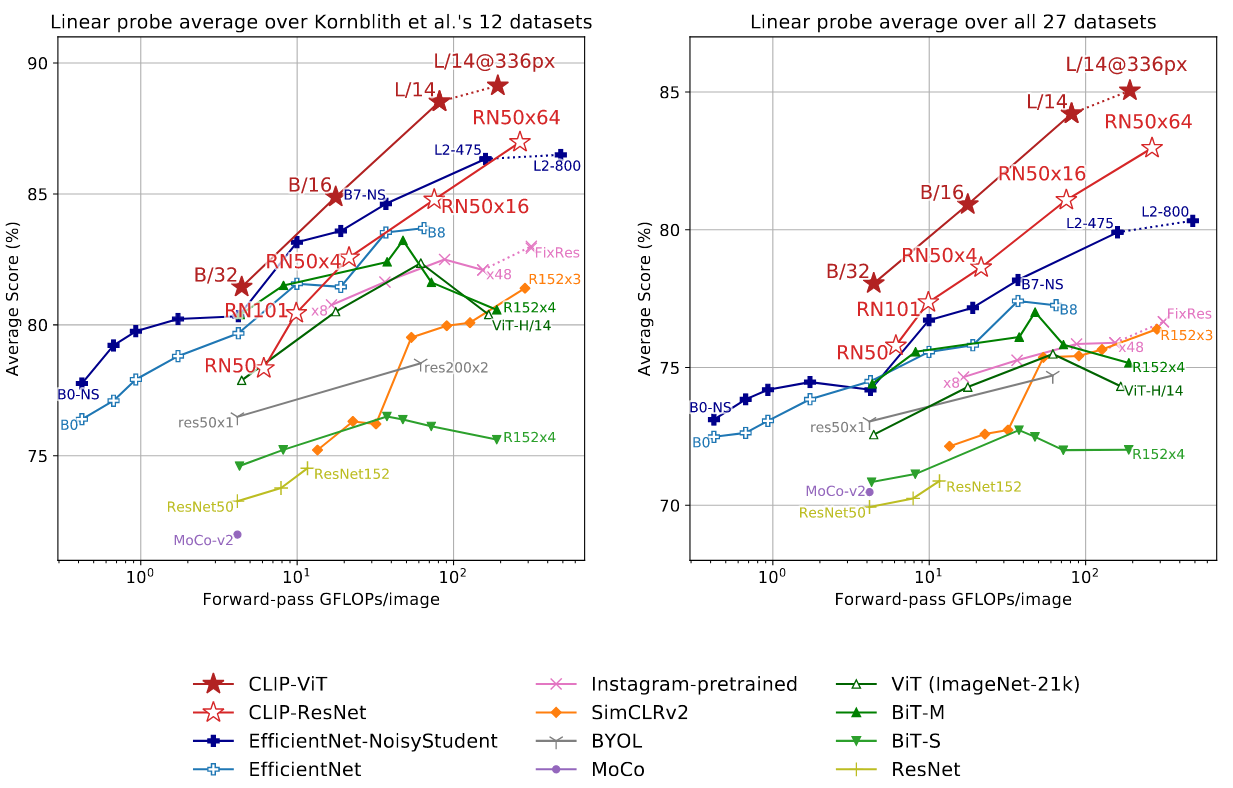
可以看到,当在足够大的数据集上训练时,视觉转换器 (vision transformers) 比卷积神经网络具有更好的效果。
Zotero 地址
Learning Transferable Visual Models From Natural Language Supervision
zotero id: 3GY8HZ4R