论文阅读_BEVFormer
介绍
英文题目:BEVFormer: Learning Bird's-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers
中文题目:BEVFormer: 通过时空 Transformers 从多摄像头图像学习鸟瞰图表示
论文地址:https://arxiv.org/pdf/2203.17270v1.pdf
领域:机器视觉,自动驾驶
发表时间:2022 年 3 月
作者:Zhiqi Li 等
出处:南京大学,上海人工智能实验室,香港大学
代码和数据:https://github.com/zhiqi-li/BEVFormer
阅读时间:2022.05.22
读后感
文中方法和特斯拉视频(特斯拉2021人工智能日AI Day完整视频)架构相似。比较有意思的地方是在BEV 层面结合了时间和空间信息。
介绍
在 3D 感知领域,雷达已取得了很好效果,机器视觉近几年也受到关注,除了成本低,相对雷达,它还能感知远距离物体,以及识别道路标识。
BEV 鸟瞰图从多个摄像头信息计算表征,用于描述周围场景。分割任务证明了 BEV 的有效性,但由于该方法基于深度信息生成 BEV 容易出错,所以在三维目标检测方面效果不显著。
另外,时间信息也很重要,比如车往前开的时候,现在被遮挡的物体,之前可能是能看到的。但是目前用到时序数据的不多,主要因为运动中的情况不断变化,不能通过简单堆叠前帧的方法来辅助当前预测。
文中提出了结合多摄像头和历史 BEV 特征的方法 BEVFormer,如图 -1 所示:
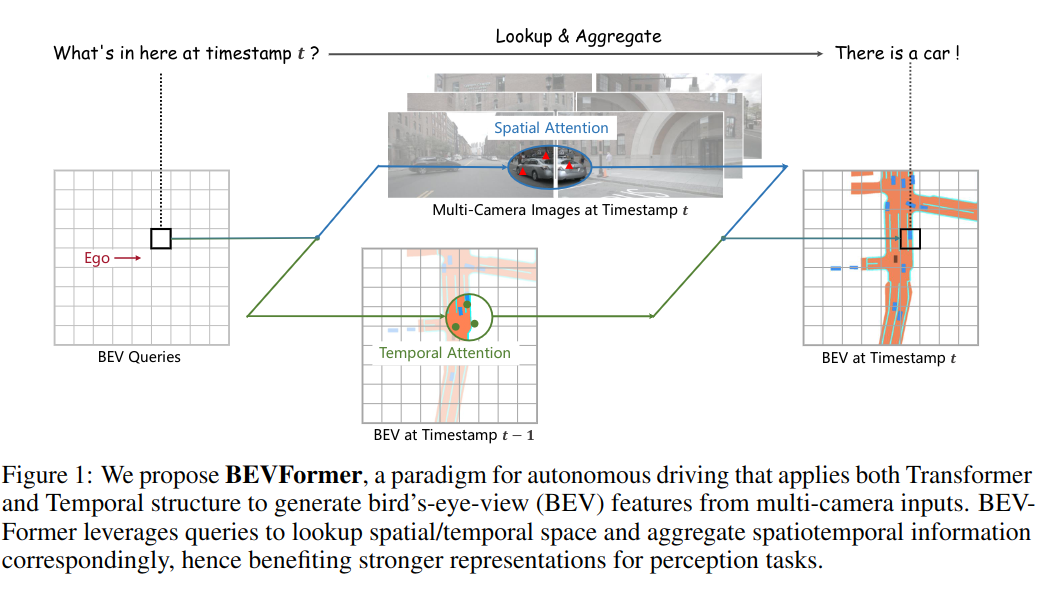
左图是BEV 的网格图,即鸟瞰图,Ego 是汽车本身,黑色方块是关注的物体;中图的交叉注意力结合了多个摄像头信息的空间信息;右图使用自注意力模型,结合了之前数据的 BEV 信息。以此来解决估计运动物体的速度和检测严重遮挡物体的问题。
文章贡献
- 提出 BEVFormer,结合时空信息,支持下游任务。
- 使用自注意力和交叉注意力,将特征结合到 BEV。
- 实验效果好。
DEVFormer
总体架构
BEVFormer 有六个 Encoder 层,每层如图 -2 所示,
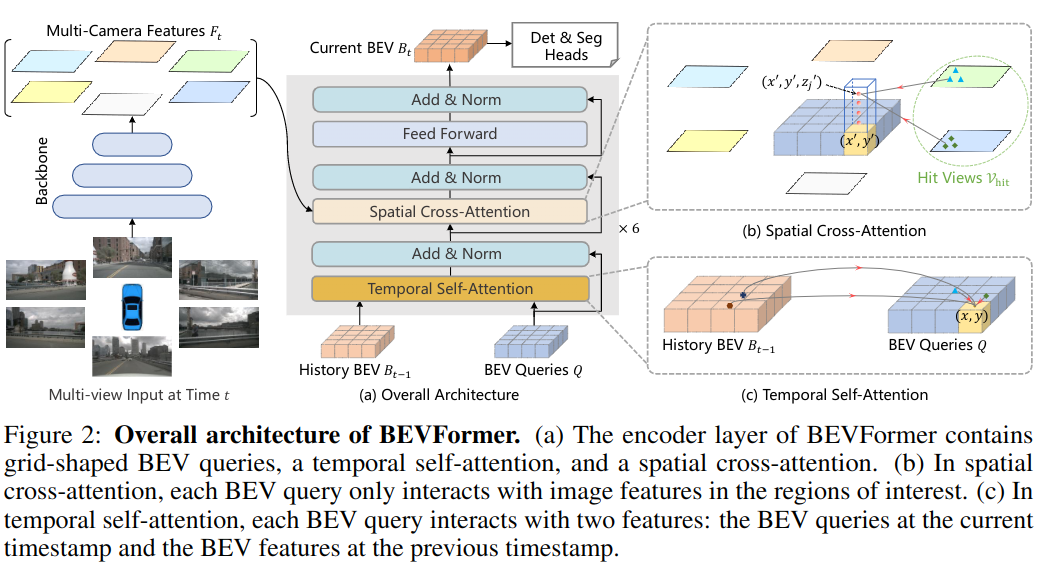
左图描述了车载的 6 个摄像头,通过底层 Backbone 提取多层图像特征(Feature Map);中间图 (a) 展示了一个编码层包含时间的自注意力和空间的交叉注意力,空间信息由左图提供,它的输入还包括前一层的网格 BEV 特征 (橙色) 和 BEV 查询 (蓝色),输出是 BEV 特征;右侧的图 (b) 细化了空间交叉注意力,BEV 查询只与它感兴趣的摄像机图片特征交互;右图 (c) 细化了时间自注意力,查询与之前的 BEV 特征和当前的 BEV 特征交互。
其中 BEV 查询是网格形状的可学习参数,用于从摄像头中查询 BEV 特征。
预测阶段,在时间 t,读取多摄像头的图片特征 F,以及 t-1 时刻的 BEV 特征,通过上述处理,输出 BEV 在 t 时刻的特征,送入下一层;多层处理完最后输出的 BEV 特征送入下游任务。
BEV 查询
定义一个网格形状的可学习的参数 Q ∈ RH×W×C,其中 H,W 是 BEV 平面的大小,其中每个点 p=(x,y) 指向现实世界中 s 米的区域,每个点对应一个大小为 C 的查询 Qp。BEV 的中心点一般是汽车本身所在的区域。依照惯例,在输入 BEVFormer 框架前,将位置嵌入到 Q 查询中。
空间交叉注意力
多个摄像头,每个摄像头又有多层特征输出时,数据量非常大,因此使用了多头注意力。具体使用形变注意力 deformable attention(一篇非常精典的论文)。BEV 查询使每个点只与某些摄像头(视图)相关。
本文将形变注意力从 2D 扩展到 3D。如图 -2(b) 所示,先将查询扩展成了一个柱形,采样 3D 参考点,再投影到 2D。把与某点相关的视图记作 Vhit。把 2D 点作为查询 Qp 的参考点,从相关视图中这些点周围采样。最终得到采样特征的加权和作为空间交叉注意力的输出:

式中的 i 是摄像头索引,j 是参考点,N 是柱中所有高度参考点,F 是特征,Q 是查询,P(p,i,r) 是投影函数,用于获取第 i 图中的第 j 个参考点。
使用投影函数计算参考点方法如下:
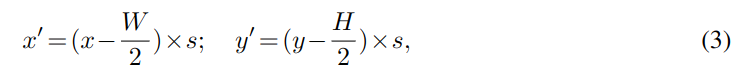
x',y' 是真实世界坐标,x,y 是 BEV 上的坐标,W,H 是 BEV 大小,S 是每个 BEV 小格对应现实世界的米数。
现实中,不仅有位置 x',y',还有高度 z',对于每个查询点 p,获取一个 3D 柱
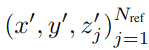
,通过相机的投影矩阵将三维参考点投影到不同的图像视图上。
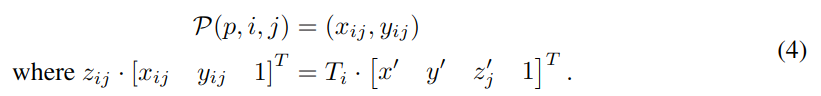
此处的 P(p, i, j) 是由第 j 个 3D 点 (x', y',z'j) 投影到第 i 个视图上的 2D 点,Ti 是第 i 个相机的已知投影矩阵。
时间自注意力
通过结合历史 BEV 来表征当前环境。查询 Q 和前一时间的 Bt-1,首先要对齐运动中的 Bt-1 和 Q,将对齐后的 B 记作 B',由于物体在运动中,因此,通过自注意力建模:

与之前的形变注意力不同的时,此处的位置偏移∆p 是通过串联 Q 和 B't-1 来预测的。
相对于简单的堆叠之前的 BEV,自注意力更有效地对长时依赖建模,也减少了计算量和信息干扰。
应用 BEV 特征
Encoder 输出的 DEV 特征 Bt 大小为 HxWxC,可用于自动驾驶的 3D 物体探测(预测三维边界框和速度,无需 NMS 后处理)和地图分割等任务中。
实现细节
训练阶段
从过去 2s 中随机抽取 3 个样本,表示为 t-3,t-2,t-1,t,在时间 t,根据多摄像头的输入和 Bt-1 生成 Bt,Bt 包含四个样本的时空信息,最终输出到下游任务,计算损失函数。
预测阶段
对视频中的每帧计算,并保留 BEV 特征用于后续计算,尽管使用了时间信息,但是文中方法的预测时间与其它方法差不多。
实验
数据集
实验使用两个公开的自动驾驶数据集:nuScenes 和 Waymo。
nuScense 包含 1000 个,每个约 20s 的数据,标注 2Hz,每个样本包含 6 个摄像机具有 360 度的水平场景。对于目标检测任务有标注了 1.4M 个 3D 框,共包含 10 个类别。5 种评价标准:ATE, ASE, AEO, AVE, AAE,另外,nuScense 还提出了 NDS 来计算综合评分。
Waymo Open Dataset 包含 798 个训练序列和 202 个验证序列,每帧 5 张图片,摄像机具有 252 度的水平场景,但提供了 360 度的标注。由于 Waymo 是高分辨率且高采样的,所以利用 5 秒采样切分数据,并只检测车辆类别。
实验设置
基础模型使用使 ResNet101-DCN 和 VoVnet-99,三层 256 通道的 FPN,BEV 大小为 200x200,每小块对应 0.512 米,用 6 层编码层,从 -5 米到 3 米取 4 个高度的参考点,24 次迭代。由于 Waymo 不能取到 360 度全景,由此对 BEV 大小做了调整。
基线使用 VPN 和 Lift-Splat 模型做对比,另外,还对比了不使用时间信息的 BEVFormer-S 模型。
3D 目标检测

Modality 中 L 表示雷达,C 表示摄像机,可以看到 BEVFormer 与雷达效果相似。另外,对于速度 mAVE 也有明显提升。
多任务感知
针对 3D 检测和地图分割同时训练两种任务,以节省资源,结果如表 -4 所示:
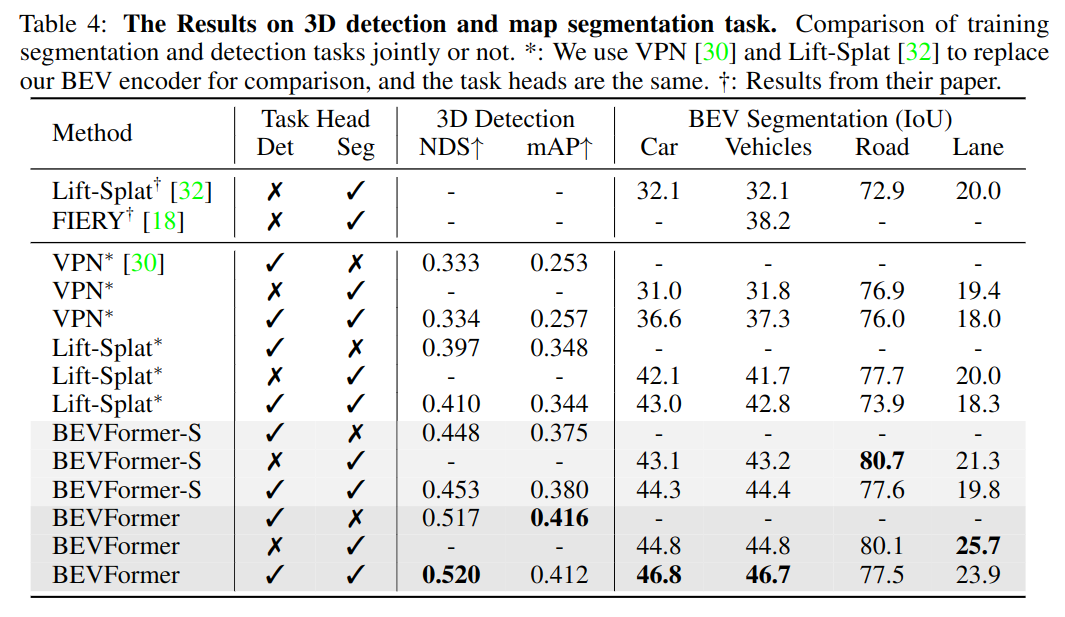
可以看到,在车辆分割中多任务训练效果更好,而道路和车道分割效果较差,这可能是负迁移导致的。
消融实验
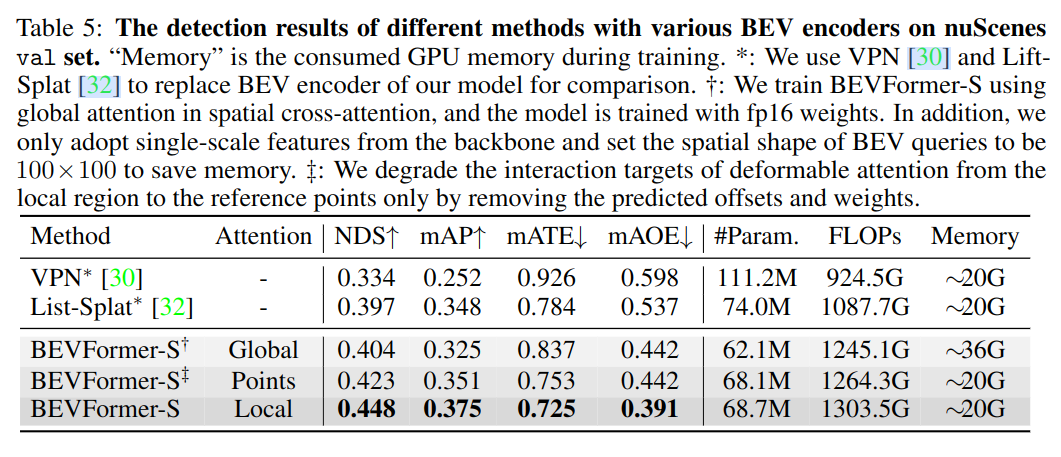
空间交叉注意力
与之前模型相比,使用了 Deformable 的 BEV 模型有明显提升。相对于全局注意力,只关注参考点的注意力(限制了感受野),稀疏注意力利用了先验的感兴趣区域,取得了更好效果,且相对比较节省资源。
时间自注意力
通过 BEVFormer 与 BEVFormer-S 的比较可以看出,使用时间注意力的效果,其优势如下:更好地预测速度;预测位置方向更准确;对遮挡物体有更高召回率。
模型规模和延迟
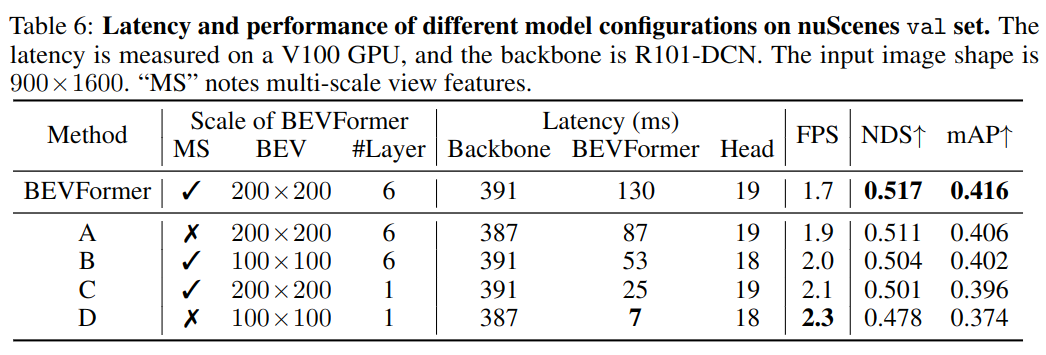
由于需要处理多视图,时间主要用于 backbone 模型;另外,缩减了 BEVFormer 后,效果下降也能接受。
可视化效果

如图 -4 所示,模型只在较远和小型物体识别有误。