论文阅读_Kosmos-1
1 | name_ch: 语言并非你所需要的全部:让感知与语言模型保持一致 |
读后感
文章主要研究视觉和文本领域的对齐,具体应用是看图回答问题。
文中做了大量工具,在评测部分可以看到它在多领域多个数据集上对模型进行了评测,很多领域做了尝试。文中也没太说具体是怎么做的,主要是提出概念,展示能力。

摘要
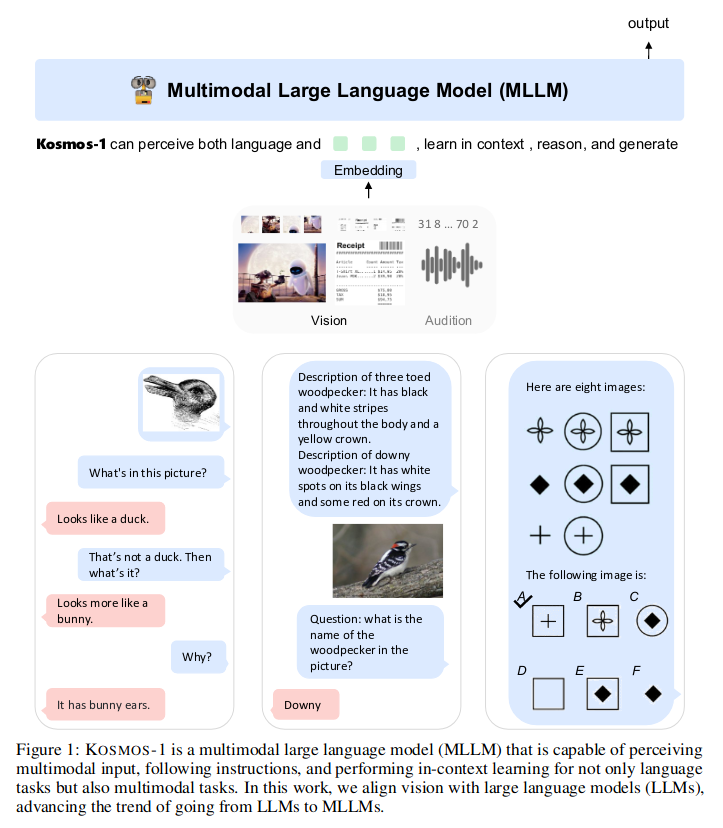
KOSMOS - 1 是一种多模态语言模型,能够感知通用模态、遵循指令、在语境中学习并产生输出。
The limits of my language means the limits of my world. Ludwig Wittgenstein
作者还引用了一句话:我的语言的极限意味着我的世界的极限。
KOSMOS-1 的优势:
- 语言理解,生成,甚至 OCR - free NLP (直接以文档图像为输入)
- 感知语言任务,包括多模态对话,图像描述,视觉问答
- 视觉任务,如 (通过文本指令指定分类) 描述的图像识别上取得了令人印象深刻的性能。
介绍
文中提出了三种新的拓展:
- 从 LLM 到 MLLMs:更自然的交互方式
- 将语言作为通用接口
- MLLMs 提供的新能力
KOSMOS-1 多模态自然语言模型
输入表示
数据描述:

将嵌入信息送入解码器。对于输入令牌,使用查找表将其映射为嵌入。
使用重采样器作为注意力池化机制,减少图像嵌入次数。
多模态大语言模型
使用 TorchScale 底层库,MAGNETO 和 xPOS 技术。
训练对象
包含单模态数据和多模态数据。使用单模态数据进行表示学习。例如,利用文本数据进行语言建模预训练指令跟随、语境学习、各种语言任务等。此外,用跨模态对和交错数据学习将一般模态的感知与语言模型对齐。
训练
多模态训练数据
文本
见附录 B.1.1
文本数据对
见附录 B.1.2
交错的图文数据
见附录 B.1.3
训练设计
MLLM 组件有 24 层,隐藏维度为 2048,FFN 中间尺寸为 8192,注意力头为 32,产生约 1.3 B 的参数。
图像表示从一个预训练的 CLIP ViT-L/14 模型中获得,该模型具有 1024 个特征维度。
纯语言指令调优
使用 Unnatural Instructions 和 FLANv2 数据进行指令调优,以使模型更好拟合人的指令(instructions)。
具体见附录 A.2。
评测
分别在自然语言任务,交叉模态转换,非言语推理,语言感知和视觉任务中对模型进行评测。
语言感知任务
主要针对图像描述和看图回答问题。
智力测试(非语言推理)
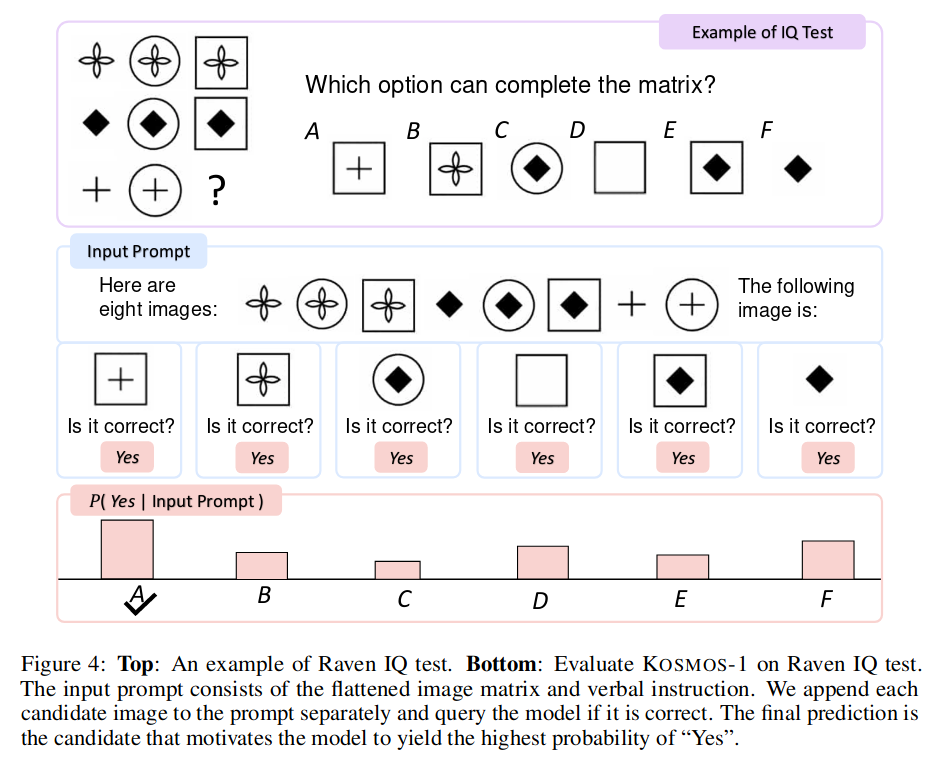
虽然分不高,但是明显比随机回答(瞎蒙)要好。
不使用 OCR 的自然语言理解
不使用 OCR 技术,直接理解图片中的文本。
根据网页回答问题
略……
多模态思维链提示
生成一系列推理步骤,并将多步问题分解成中间步骤,可以显著提高问题的求解效率。
Zero-Shot 图像分类
带描述的 Zero-Shot 图像分类
提供上下文描述可以显著提高图像分类的准确率。

自然语言任务
与 LLM 水平差不多
模态转换任务
语言到多模态
利用语言指令调优,提升其它模态的认识水平。
多模态到语言
利用视觉常识推理,将视觉知识迁移到语言任务中。