论文阅读_音频压缩_SoundStream
name_ch: SoundStream:一种端到端的神经音频编解码器
name_en: SoundStream:An End-to-End Neural Audio Codec
paper_addr: http://arxiv.org/abs/2107.03312
date_publish: 2021-07-07
1 读后感
高效压缩语音、音乐和一般音频。模型由编码器,量化器,解码器组成,主要使用了卷积技术。
2 摘要
基于神经网络的音频编码器,可高效生成文本,音乐。模型结构由全卷积编码器/解码器网络和残差矢量量化器组成。它结合了对抗和重建损失技术,可将量化的嵌入作为输入,生成高质量音频。
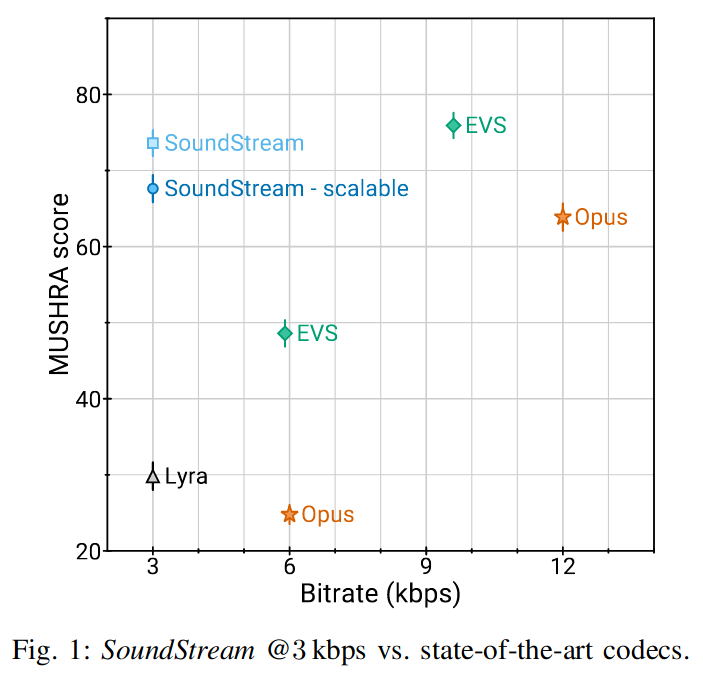
单模型生成 3kbps~18kpbs 的音频。该模型适用于低延迟实现,支持流式推理,并可在智能手机 CPU 上实时运行。通过主观质量证明,SoundStream 输出音频高于之前模型。
3 介绍
主要贡献:
- 提出音频编码器 SoundStream,由编码、解码、量化器组成;通过重建和对抗损失训练模型,实现高品质音频生成。
- 提出新的残差量化器,平衡速率/失真/复杂度;提出 quantizer dropout,使单个模型能处理不同比特率。
- 对于采用梅尔图谱特征的解决方案,编码器带来了非常显著的编码效率提升。
- 主观评测中证明,其输出音质高于之前模型,其 3kbps 的效果在主观评估中优于 12kbps 的 Opus 和 9.6kbps 的 EVS。
- 模型可在低延迟下运行,部署在智能手机上时,可在单个 CPU 线程上实时运行。
- 提出了一种 SoundStream 编解码器的变体,可以联合音频压缩和增强,而不引入额外的延迟。
4 方法
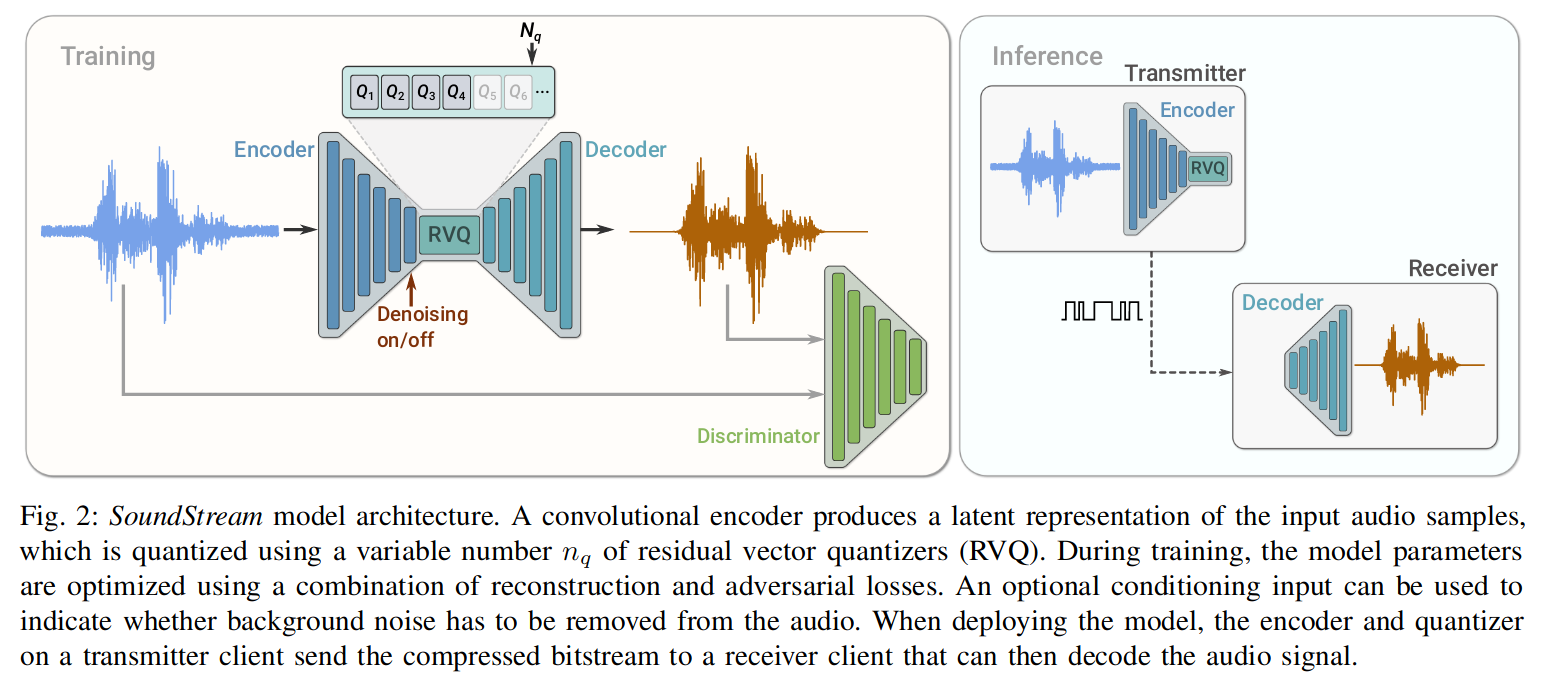
模型由三部分组成:
- 编码器:卷积 Encoder 将采样率为 fs 的输入音频 x 转换为嵌入序列。
- 残差向量量化(RVQ):将嵌入通过 codebooks,压缩成少量字节(目标位数)的表示,生成量化嵌入。
- 解码器:从量化的嵌入中产生有损重建 x^。
其训练过程中还用了一个判别器 Discrminator,它结合了对抗和重建损失,并使用可选的条件输入,用于指示是否从音频中去除背景噪声(Denosing)。
部署模型时,Transmiter 的编码器和量化器将压缩,由 Receiver 解码音频信号。
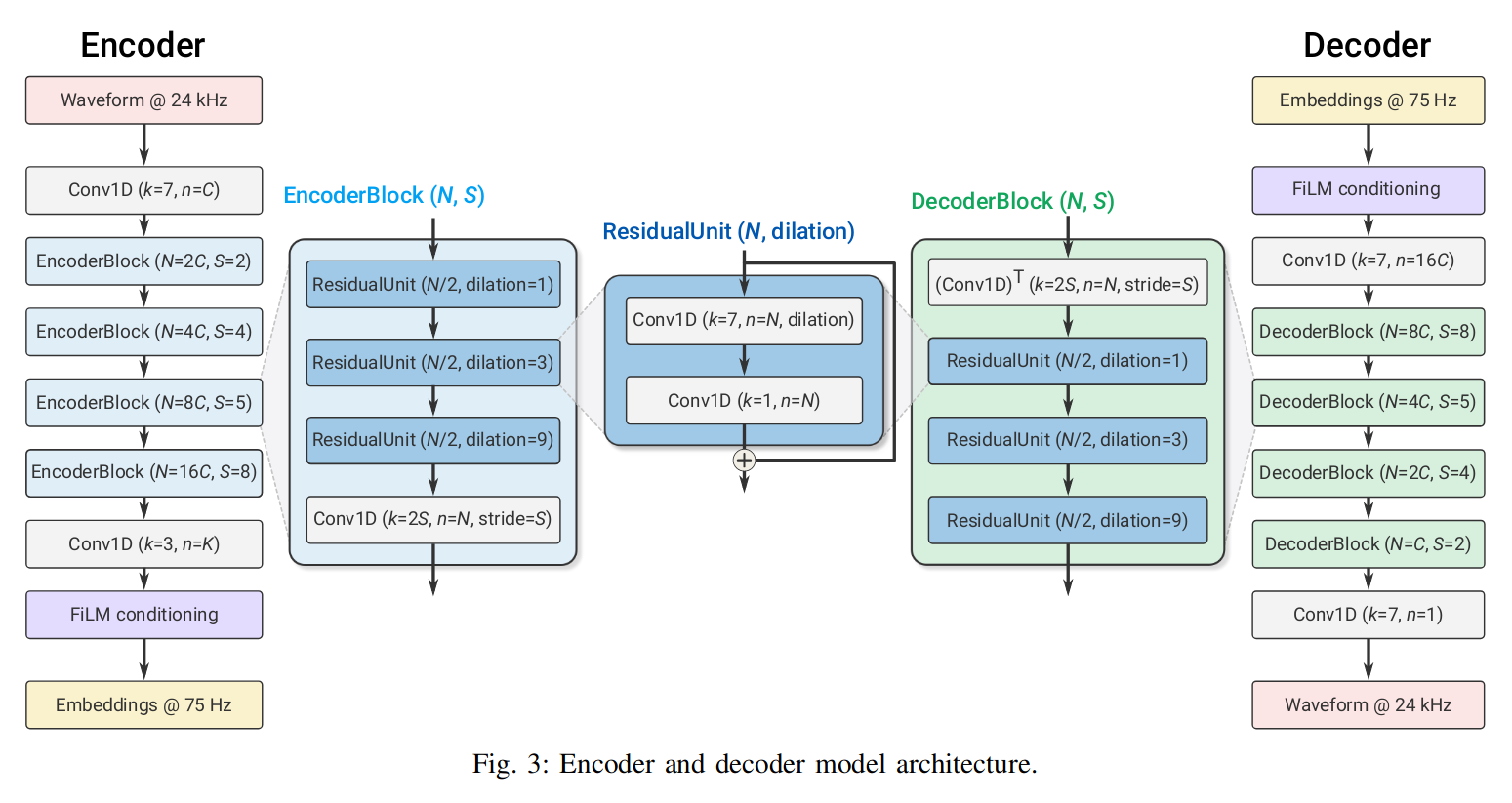
4.1 编码器结构
其输出维度是 SxD,D 是 Embedding 的维度,S = T /M,其中 T 是时间 M 是不同层(跨度)的输出如图中的:M = 2 · 4 · 5 · 8 = 320;如图每个 Encoder 由多个 EncoderBlock 组成,而 EncoderBlock 又由 ResidualUnit 组成。
4.2 解码器结构
解码器类似于编码器的逆过程,把降采样变成了升采样。
4.3 残差向量量化
量化器的目标是压缩编码器产生的嵌入,转换到指定的字节长度。它学习一个 N 个矢量的码本来编码 enc(x) 的每个 D 维帧。然后将编码后的音频 S×D 映射到形状为 S × N 的 onehot 向量序列。
4.4 判别器结构
定义了两个不同的鉴别器:
- 基于波型的鉴别器,它接收单个波形作为输入;
- 基于 STFT(快速傅里叶变换)的鉴别器,它接收输入波形的复值 STFT 作为输入,以实部和虚部表示。
两个鉴别器都是完全卷积的,因此输出中的逻辑数与输入音频的长度成正比。
4.5 训练目标
\[ g(x) = dec(Q(enc(x)) \]
输入音频是 x,最终输出音频 x^=g(x)。保证生成的保真度和质量。
鉴别器用于判断语音为原始语音还是生成语音:
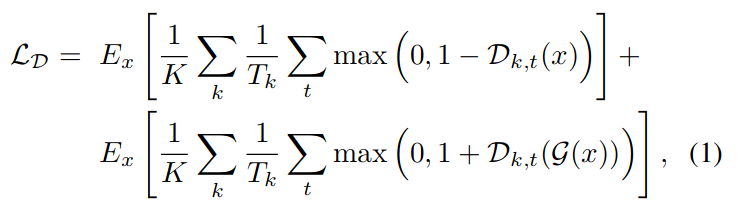
生成器的对抗损失是:
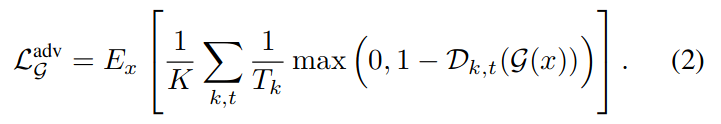
为了提高信号保真度,还采用了两个额外的损失:特征损失 Lfeat,在鉴别器定义的特征空间中计算;多尺度光谱重建损失 Lrec:
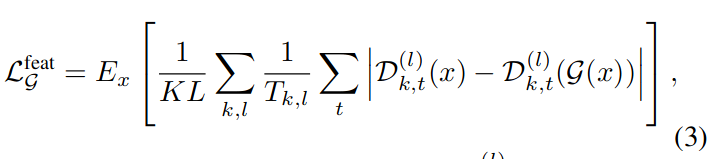
其中 L 是模型内部的层数,用于对比每一层的原始数据与生成数据的差别,计算其平均绝对误差。
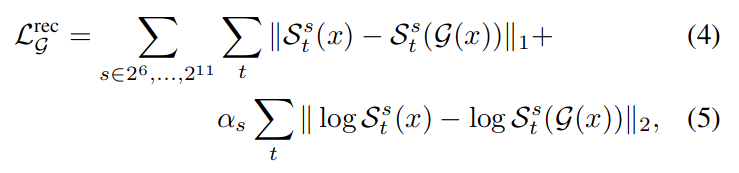
这里的 S(x) 用于计算梅尔倒谱。
从损失函数中可以看到,除了深度学习对抗学习的方法,这里还引入了描述音频的梅尔倒谱,傅里利变换提取特征的方法,用于衡量生成音频与原始音频的差异。
最终的误差结合了上述三种误差:
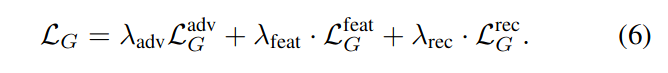
4.6 结合压缩和增强
SoundStream 设计为压缩和增强可以由同一模型联合进行,而不会增加整体延迟。
提供代表两种模式(去噪启用或禁用)的调节信号,使模型可同时支持生成带背景声的音频和去噪的音频。具体方法是引入了特征线性调制 (FiLM) 层。