GPT SoVITS语音合成模型原理
1 简介
GPT_SoVITS 可以说是目前最好的中文语音合成模型。我没有找到它的论文和原理说明,然后通过扒代码,脑补了一下其原理。
GPT_SoVITS 不是一个端到端的工具,相反,它是一个由多个工作组合而成的工具链。其核心是 GPT 和 SoVIT 两个模型,这两个模型需要根据不同发音人进行 fine-tune。外围包含去背景音乐、语音识别、去噪、切分、提取音频特征、提取文本含义等多个现成工具,可直接使用。
可以将其分为训练和推理两个阶段来看。训练阶段的输入是目标发音人的音频,输出是经过精调后的模型;推理阶段的输入是文字和语音提示,输出是合成后的音频。
2 核心模型
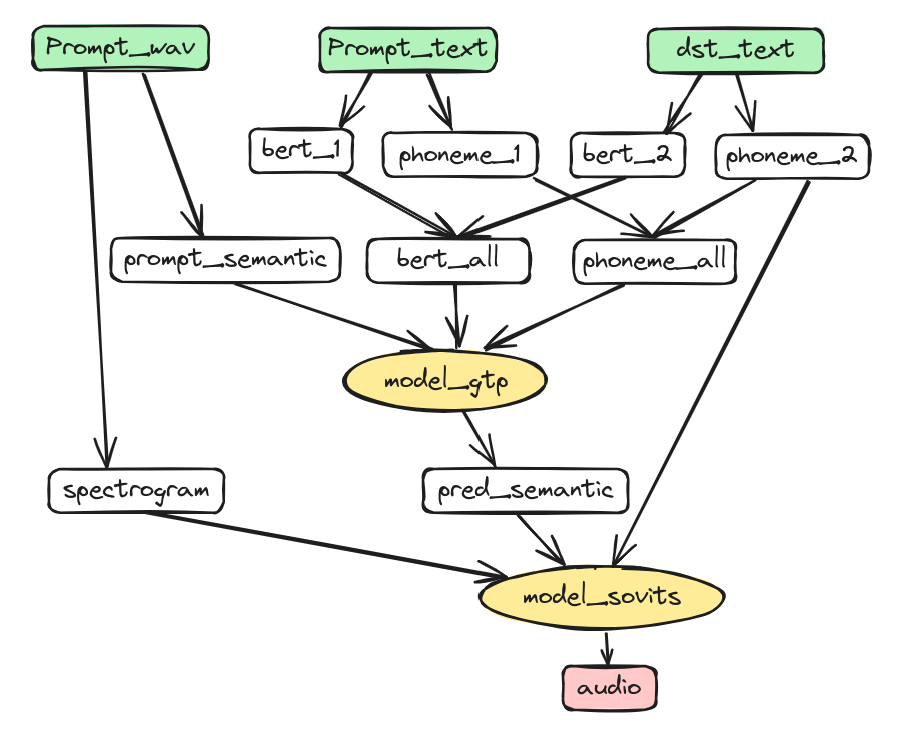
(推理部分图示)
为了避免混淆,在这里我们尽量不使用“语义”这个词。BERT 模型输出的是我们通常所说的“语义”,在这里我们将其称为“文本含义”。而 Semantic 也被翻译成中文的“语义”,而 cnHubert 模型输出的 Semantic 指的是一种混合了音素和文本含义的概念,我们将其称为“统计音素”。
下面通过分析推理过程来看看这些模型是如何协调工作的。从上图可以看到推理过程中模型 (黄色) 和输入 (绿色) 和输出 (红色)。在推理过程中涉及了四个模型:bert_model 模型、ssl_model 模型、t2s_model 模型(GPT 模型)和 vp_model 模型(SOVITS 模型)。这些名称与推理代码保持一致。
2.1 bert_model
- 功能:将文本转换成文本的的内在含义数据,它结合了上下文的意思,让后续模型在合成语音时参考说话的内容。
- 模型:chinese-roberta-wwm-ext-large,它是常用的 bert 中文模型之一,基于 RoBERTa 架构下开发,其中 wwm 代表 Whole Word Masking,即对整个词进行掩码处理;英文利用不同库提取音素。在这里不精调直接使用。
- 模型输入:输入为中文文字,即 prompt_text, dst_text
- 模型输出:输出为 bert_1,bert_2
- 说明:由于它不是主模型,也不需要在此调参,上图中就没把它画出来。
- 相关代码:GPT_SoVITS/prepare_datasets/1-get-text.py
2.2 ssl_model
- 功能:从音频中提取音频特征,hubert 方法在语音识别中常被用到,通过统计方法(如聚类)从音频中直接提取,比拼音者音标更能细致地描述声音的本质。
- 模型:chinese-hubert-base,这个模型使用自监督方法训练,用于中文统计音频提取,无需训练即可直接使用。
- 模型输入:音频数据
- 模型输出:模型输出音频特征 ssl,看代码是再通过 SoVit 的生成模型中通过卷积和量化映射到成 token,作为统计音素 semantic。
- 说明:由于它不是主模型,也不需要在此调参,上图中就没把它画出来。
- 相关代码:GPT_SoVITS/prepare_datasets/2-get-hubert-wav32k.py
2.3 t2s_model
- 功能:根据上文的文本含义 bert_1、待合成的文本含义 bert_2、上文的音素(中文中的音素是拼音)phoneme_1,待合成文本的音素 phoneme_2,上文的统计音素 prompt_semantic,生成待合成文本对应的统计音素。
- 模型:
- 预测训练模型 s1bertxxxx.ckpt
- 它是主模型之一,即 GPT_SoVITS 中的 GPT
- 提供预训练模型下载,并最终使用经过特定语音精调后的新模型
- 模型输入:音素(phoneme)、统计音素(semantic)、文本含义(bert_feature)
- 模型输出:统计音素(semantic)
- 说明:GPT 通常指只有 Decoder 部分的 Transformer 结构,其具体功能是通过上下文和环境生成下文。语音生成过程也是类似,当前生成的声音不仅与说话人和当前说话内容相关,还与上下文相关。因为语音是时序数据,无法获取下文信息,因此只能参考上文。在这里需要对预训练模型进行 fine-tune 的原因是不同的人在表达相同意思时产生的统计音素可能不完全相同。
- 相关代码:
- GPT_SoVITS/s1_train.py
- GPT_SoVITS/AR/*
2.4 vp_model
- 功能:根据 GPT 模型预测的统计音素、待生成文本对应的拼音和参考音频,生成目标音频。
- 模型:
- 预测训练模型 s2G488k
- 主模型之一,即 GPT_SoVITS 中的 SoVITS
- 对抗学习训练一个生成模型一个判别模型,最终推理时使用了生成模型
- 提供预训练模型下载,最终使用特定语音精调后的新模型
- 模型输入:GPT 模型预测的统计音素、待生成文本对应的拼音、参考音频。
- 模型输出:目标音频。
- 说明:预训练出的模型与具体人声无关,这里通过 fine-tune SoVIT 模型来学习统计音素 semantic、音素 phoneme 以及具体某个人声音的具体特征之间的关系。比如某人因为口音而不分 s/sh 的情况下,需要进一步在他的声音和普通话音素之间学习映射关系,说话的语速等。
- 相关代码:
- GPT_SoVITS/prepare_datasets/3-get-semantic.py
- GPT_SoVITS/s2_train.py
- GPT_SoVITS/module/*
3 辅助模型
上面介绍了模型的推理逻辑,而训练部分更为复杂。由于 GPT_SoVITS 工具面向大众使用,因此需要支持各种长度、音质和可能带有背景音乐的音频。在训练过程中,还需要将音频与音素(拼音)对齐后输入模型。
所以作者提供了以下工具组合来处理音频:
1 | flowchart LR |
3.1 分离背景音效模型
- 原理:Ultimate Vocal Remover 5 (UVR5) 是一款基于深度神经网络的去声器。它的目标是去除人声,保留乐声。此处用该工具提取人声可能会遇到一些问题。另外,需要自行下载模型。
- 相关代码:tools/uvr5/
- 相关资料:论文阅读_去声器_UVR5
3.2 切分语音
- 原理:用判断音频信号强度阈值的方法 rms 将音频切分成 5s 左右的小段。
- 相关代码:tools/slice_audio.py
3.3 去噪模型
- 原理:调用达摩院的降噪模型实现去噪功能。
- 相关代码:tools/cmd-denoise.py
3.4 语音识别模型
- 原理:支持 openai 的 whisper 和达摩的 funasr_asr;我使用达摩 ASR 中文,即 funasr,端到端的语音识别包,可在本地使用,需要下载:语音端点检测 vad, 语音识别 asr, 标点断句 punc 三个模型。这里也是直接调库。
- 相关代码:tools/asr/*
4 其它代码
4.1 部署相关
- GPT_SoVITS_Inference.ipynb: 用于部署时安装数据
- gpt-sovits_kaggle.ipynb:用于部署时安装数据
- colab_webui.ipynb:用于部署 colab
4.2 界面入口
- ./GPT_SoVITS/inference_webui.py # 推理工具, 端口 9872
- ./tools/subfix_webui.py # 修改音频与文本对齐工具,端口 9871
- ./tools/uvr5/webui.py # 去背景音效工具,端口 9873
- ./webui.py # 主界面, 端口 9874,其它功能均在此调用
5 命令行调用
在这个项目中,作者主要提供了由 gradio 开发的图形界面实现功能。然而,在具体生成语音时,常常需要进行批量操作,例如一次生成多个人声的模型。这就需要在界面上输入大量内容,非常麻烦。
因此,希望能够实现更自动化的训练:输入一个音频,自动执行上述过程,并生成直接可用的模型。实际上,上述的 webui.py 也是通过调用子模块来实现的,只是传参部分需要少量调整。另外,感觉推理相关的三个程序将逻辑和界面写在一起了,存在一些重复内容。希望能够将推理的逻辑提取出来。还有提示的语音和对应的文字需要用户上传,使用起来也比较麻烦,最好能够在训练时自动抽取。
于是我就 fork 了一份代码,对上述问题进行了调整,如果需要,请参考:
https://github.com/xieyan0811/GPT-SoVITS_cmd